
当收到第一百份问卷回复的时候,我以为研究工作的难点已经过去了。样本容量够大,问题覆盖了用户的基本使用情况,数据也清晰明确,有 68% 的用户每天使用产品超过一次,82% 的人认为现有功能基本满足需求,收藏功能的满意度评分是 3.8 分(满分 5 分)。
但实际情况,和我们认为的情况恰恰相反,这些数字其实很难被真正使用。这倒不是因为收集工作做得不够认真,而是问卷只能告诉我"有多少人这样做",但无法告诉我"这些人是谁、他们在做什么、为什么会这样"。尽管我手上有一百份答案,但对目标用户的理解并没有比做问卷之前深入多少。
要知道访谈、问卷、行为数据,这三种研究方法,所解决的问题是完全不同的,三种研究方法,无法用同一个纬度去评估谁比谁更高级,它们彼此各有用途,各有边界。
一、访谈的局限在哪里
要理解问卷和行为数据各自解决什么问题,先要看清访谈的边界——它覆盖不到的地方,才是另外两种方式的用武之地。
1. 访谈的样本量小,不能代表全体用户。
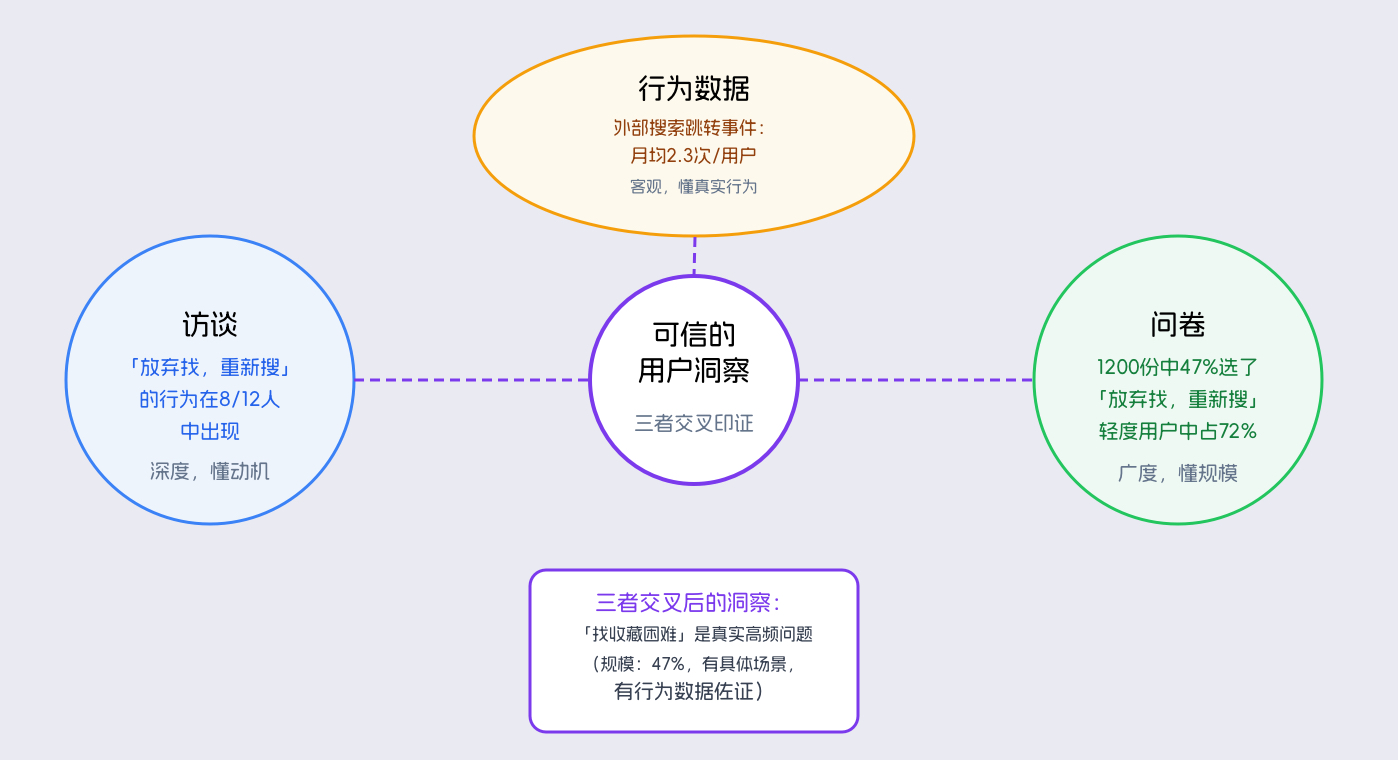
受访用户在找历史收藏时会放弃产品内搜索,直接去外部重新搜图。十个人里有八个人会这样做,这个倾向在你的样本里是真实的——但十个人的八成和一千个用户的八成不是一回事。小样本里的高比例可能是偶然聚集,只有在大样本里复现,才能确认它是一个普遍存在的问题,而不只是一个有待验证的线索。访谈给不了这个确认。
2. 访谈样本不是随机的,存在系统性偏差。
能够参与访谈的用户,往往是愿意花时间和你聊、对产品有足够关注、有一定表达欲的用户。这部分人在整个用户群体里未必有代表性。你的产品可能有一大批使用频率很低的轻度用户,但这类用户参与访谈的比例极低,因为他们对产品的投入程度不足以驱动他们花三十分钟来聊这件事。某些年龄段、某些使用场景、某些职业背景的用户,可能在你的十场访谈里从未出现过。
这两个局限,是问卷和行为数据的用武之地:把访谈中观察到的倾向放到更大的样本里验证是否普遍成立,同时主动触达那些不会出现在访谈中的用户群体。
二、问卷适合做什么
1. 问卷的核心价值:验证和量化。
问卷最擅长回答一个问题:"访谈里发现的这个用户行为模式,在更大范围内有多么普遍?"
举一个例子。访谈里有六个用户提到,他们在找历史收藏时会绕过产品内搜索、直接去外部重新搜图。六个人,而且这六个人都是愿意参与访谈的活跃用户,样本偏差很明显。这时候可以设计一道问卷题:
「当你想找一张之前收藏过的图,你通常怎么做?」
- A. 直接用产品里的搜索功能
- B. 翻分类文件夹找
- C. 放弃找,直接去外部网站重新搜
- D. 问别人或者查历史记录E. 其他方式
如果问卷结果显示有 47% 的用户选了 C,那么这个访谈发现的模式就有了量化支撑,这个问题的优先级也就有了数字依据。如果只有 8% 的用户选了 C,那这个模式在活跃用户里可能是真实存在的,但在整体用户里是小众情况,优先级要做相应调整。
2. 问卷覆盖的另一个价值:填补访谈的样本空白。
访谈中你没有做轻度用户的访谈,但问卷可以触达他们。在问卷里设置筛选题,把回收的数据按活跃用户、轻度用户、不同年龄段分层来看,就能发现各群体的答案分布差异——哪些行为是所有人都有的,哪些只集中在某一类用户身上。这些差异就是画像拆分用户分群的依据。
3. 问卷做不到的事:挖动机。
你可以在问卷里问"找历史收藏是否困难",但没有办法问"上次觉得困难是什么情况,你当时在做什么,那个困难最后是怎么解决的"。问卷的答案是选项,追问的空间被切断了。用户在问卷里告诉你"有困难",你知道规模了,但还是不知道为什么,所以要想找到原因,还是要靠访谈。
三、怎么设计对画像有用的问卷
很多团队的问卷收回来之后发现数据没法用——问的不是行为而是态度,选项漏掉了真实存在的情况,或者措辞本身就在引导答案。这几个问题在设计问卷时就要尽量避开。
1. 问行为,不问态度和感受。
- "你觉得搜索功能重不重要" → 几乎所有人都会选"重要",因为选"不重要"感觉像在否定自己。
- "上个月你用了几次搜索功能" → 这是一个行为频率,可观测,用户凭记忆回答,偏差更小,对画像更有用。
问卷要测量的是行为的频率和分布,不是感受的强弱——问"做了几次"能得到可用的数据,问"觉得重不重要"只能得到一片高分。

2. 选项要覆盖所有真实情况,包括边缘情况。
如果"从来不用这个功能"是真实存在的情况,那么这个选项就必须出现。如果你的选项只覆盖"用得多"和"用得少",但缺了"从来不用",那么这个群体的数据就消失了,那么你会系统性地高估某些行为的普遍程度。
另外,"以上都不是"这个选项几乎永远应该出现,因为你的选项框架来自你自己的假设,总有你没想到的真实情况。

3. 措辞要绝对中性,不能暗示"正确答案"。
- "你认为我们的产品在帮助你提高效率方面做得怎么样?" — 这个问法预设了产品"帮助提升了效率",选项范围已经被拉向正面。
- "使用这个产品对你的工作效率有什么影响?" — 这个问法开放,允许各种方向的回答。
问卷里的引导性措辞,会系统性地偏移数据,而这个偏移很难被察觉。

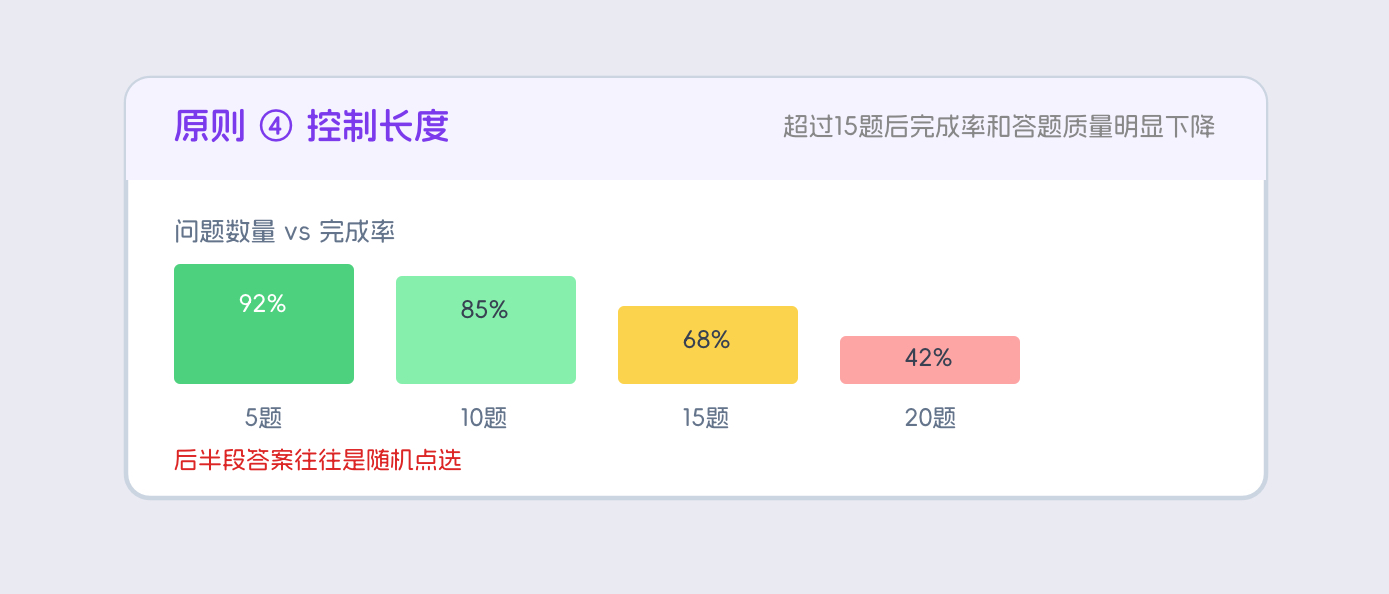
4. 控制问卷长度。
超过十五道题,完成率和答题质量都会明显下降。超过二十道题,后半部分的答案往往是随机点选——用户在疲惫,他们想的不是"这题怎么回答最准确",而是"怎么快点做完"。精简问卷不是减少信息,而是优先保留和画像研究目标最直接相关的问题,其他的删掉。
四、行为数据能补充什么
访谈和问卷收集的都是用户自己说的话,行为数据记录的是用户在产品里实际做了什么。这个区别带来几个独特的价值。
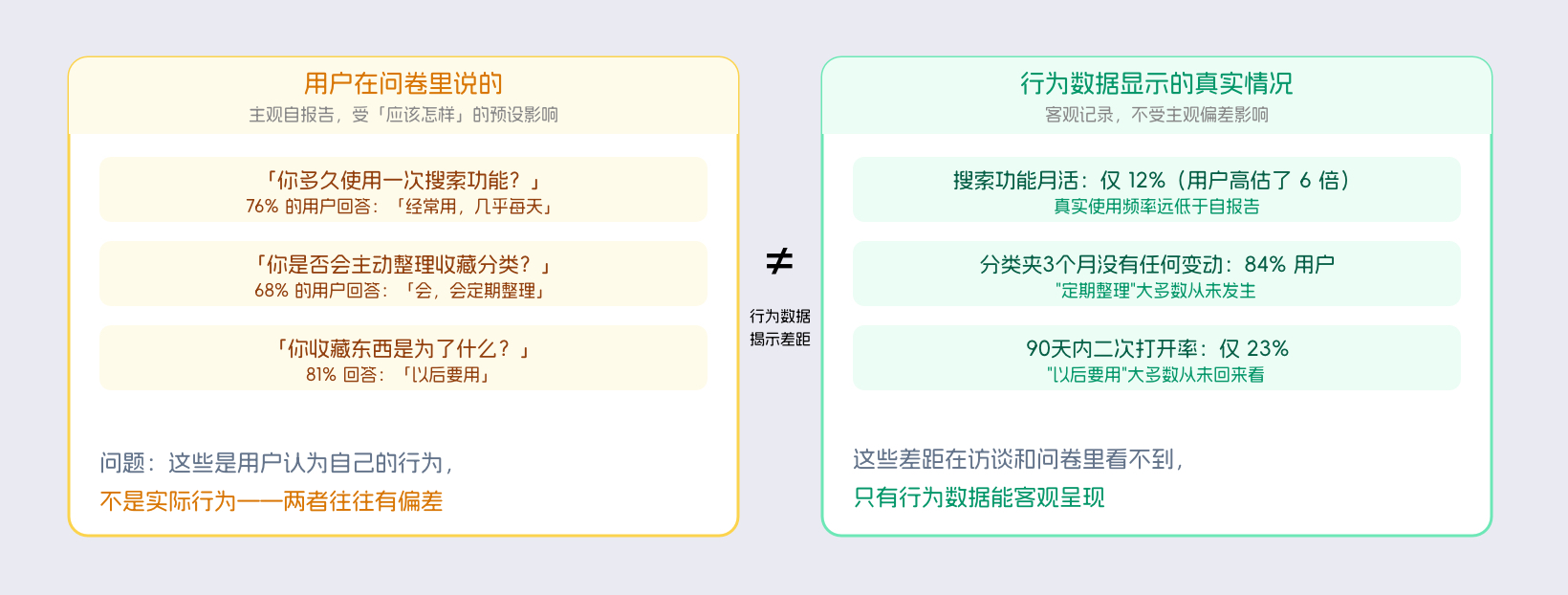
1. 行为数据揭示主观数据和实际行为的差距。
这是行为数据最重要的价值之一。用户在问卷里说"我经常用搜索功能",但行为数据显示搜索功能的月活跃用户只有 12%。两个数据都是真实的,但说的是不同的事:用户认为自己用得多,实际用得少。这种认知和行为的偏差,访谈和问卷都发现不了,只有行为数据能揭示。
这类偏差很常见,而且有固定的模式:用户通常高估自己对高频功能的使用(因为"这是好功能,我应该用"),低估自己对简单逃生路径的依赖("放弃找、直接重搜"这种行为,用户自己通常不认为是"行为模式",不会在问卷里主动选)。行为数据把这两类偏差都消除了,呈现的是实际发生的事。
2. 行为数据回答"发生了什么"。
用户在哪个步骤停下来不往前走了?哪个功能几乎从不被点击?哪条操作路径是用户实际走的,而不是设计时预期的路径?哪个页面的退出率异常高的?
这些信号指向那些需要深入研究的问题,是很好的访谈选题来源。某个功能点击率极低,在做访谈时可以专门问这个场景——是用户不需要它,还是发现不了它,还是发现了看不懂,还是实际需要,但使用门槛过高?行为数据只告诉你"异常在这里",找到原因还是要靠访谈。
3. 行为数据的限制:回答不了"为什么"。
一个页面的跳出率是 78%,这个数字本身没有告诉你任何可以直接行动的信息。可能是页面太慢、可能是内容不符合预期、可能是操作路径不清楚、可能是用户完成了任务目标,就选择离开了(离开不等于失败)、可能是这类用户本来就是低频使用的。数字只是一个现象,原因需要靠访谈来挖。
五、三种数据怎么使用
前面分别讲了三种数据各自能做什么、做不到什么。在实际使用过程中,三者是有先后顺序的,通常访谈在前,问卷跟进,行为数据贯穿始终。
第一步:先做访谈
问卷的问题和选项应该来自访谈中观察到的真实行为,而不是团队自己的假设。没有访谈做基础,很容易漏掉最重要的选项,或者把整个问卷框架建立在一个错误的前提上——收回来一百份答案,发现问的问题从一开始就偏了。
第二步:用问卷验证和扩大
访谈完成后,用问卷做两件事:
1. 把访谈中观察到的倾向放到更大的样本里量化,看它有多普遍;
2. 触达访谈没有覆盖到的用户群体。
第三步:用行为数据持续校准
行为数据不需要等访谈或问卷结束才看。在访谈之前,先看哪些功能正在被使用、用户在哪里卡住,这些可以帮你问出更有针对性的问题;在问卷收集完毕之后,用行为数据校对用户自报告和实际行为之间的差距。
六、最容易犯的几个错误
1. 跳过访谈,直接用问卷做画像。
这是最常见的错误行为。要知道问卷给出的是选项分布,不是行为场景,无法让你理解用户是谁、在做什么、为什么这样做。用问卷数据做出来的画像,通常会变成"平均人型"——每个字段都是一个比例数字,比如"78% 的用户每周使用 3 次以上,62% 的用户最关注易用性",这些数字读完之后,你没有办法在脑子里构建出一个具体的人,也没有办法从这些数字里,推断出任何有区分度的设计决策。
2. 把行为数据当作答案,而不是问题的起点。
行为数据能告诉你用户在产品里点了什么、走了哪条路,但不能告诉你他们在想什么、他们的目标是什么、让他们决定离开的是那种判断。没有访谈的行为数据,这些行为数据就成了一堆没有解释的现象。把这些现象直接写进画像,等于把"有多少人做了这件事"当作了"为什么这样做",两者之间有根本性的差异。
3. 收集了所有类型的数据,但从不把它们放在一起看。
有些团队做了访谈,也发了问卷,也有行为数据报告,但这三份材料分别躺在三个地方,做画像的时候只用了其中一份。三种数据的价值在于交叉验证:访谈里的模式在问卷里有没有量化支撑?问卷里的行为自报告和行为数据吻合吗?行为数据里的异常点,在访谈里有没有出现过对应的用户描述?这些交叉,才是数据真正有价值的地方。
七、最后
数据收集到这一步,你手里有访谈笔记、问卷结果、行为报告。这三份材料加在一起,还不是画像的全貌,这些只是做画像的原材料。接下来,我们如何从这堆原材料里拆分出清晰的用户分群,这将是我们下一篇文章的重点。
有0人收藏了本文



















