
五场测试做完了,桌上摊着五本笔记,每本记了三四十条观察;电脑里存着五段录屏视频,总时长将近六个小时;便利贴贴了半面墙,还有一些备注随手写在纸边上,字迹已经有点看不清了。
这些材料加在一起,大概有两百条原始记录。随手翻看几篇笔记,发现很难形成判断,比如第二个用户在注册页停了很久,这算不算严重问题?第四个用户跳过了邮箱验证,这是个别行为还是普遍现象?有三个用户都提到"不确定提交成功了没有",这三条观察之间有没有关联?每条记录单独看都说得通,但放在一起看,确找不出方向。
一. 测试结束后立刻做的一件事
整理数据从测试结束的那一刻就应该开始了,不是等到所有场次都结束之后才开始。
每场测试结束后,在参与者离开的那五到十分钟里,参与测试的人员需要立刻写一份快速回顾:这场测试里最值得关注的两三个发现,用户在哪里卡住、卡了多久,用户说了哪句最值得记录的原话。不需要完整,不需要结构,只需要把最鲜活的印象沉淀下来。
之所以要立刻做,是因为记忆衰减的速度比预期快得多。测试结束两小时后,很多细节的鲜活感已经消退;第二天再回忆,很多具体的行为已经模糊,只剩下一个模糊的"他在那里卡了很久",而"很久"是多久、他当时说了什么、他最后怎么处理的——这些细节已经通通丢失了。
写快速回顾的时候不需要分析,不需要得出结论,只需要把刚才最鲜活的印象用文字固定住。这样到了后续整理阶段,打开回顾就能回到当时的现场感,而不是对着一条"用户在这里卡了很久"的笔记,想不起来到底卡了多久、卡的时候说了什么。
二. 观察笔记的标准格式
原始笔记往往格式不一——有的是完整的句子,有的是关键词,有的混入了主持人的解读,有的没有记录是哪个用户或哪个任务。这种格式不统一的笔记在后续做比较时会很麻烦:不知道这条观察来自哪个用户,不知道发生在哪个流程节点,无法判断它和其他场次的笔记是否在描述同一类问题。
整理的第一步,是把所有原始笔记转换成统一的格式。每条观察需要包含四个要素:
- 谁:哪位参与者。用编号(P1、P2、P3)而不是真名,便于后续分析时在多条笔记里看到"P1 和 P3 都遇到了这个问题"这样的信息。
- 做了什么:具体的行为描述。动作、操作对象、发生了什么,越具体越好。
- 在哪个步骤:任务几,流程的第几步。这个定位让多场测试里的同类观察可以被放在一起比较——"五个用户都在任务二的第三步遇到了障碍"这个规律,只有在每条笔记都有步骤定位的情况下才能看出来。
- 反应:用户的情绪反应或语言输出,如果当时有记录的话。用户的原话比主持人的概括更有价值,哪怕只是半句。

举个例子。同一个观察,标准化前后的区别:
- 标准化前:"P2 找不到收藏,很迷茫。"
- 标准化后:"P2 / 任务一第二步 / 在商品详情页停留 45 秒,手指划过收藏图标两次但未点击,最后点击了加购按钮 / 说'我想存起来看,但不知道放哪'"
标准化前的写法只有一个模糊的判断("找不到""很迷茫"),到了分析阶段,设计师看不出用户具体做了什么、在哪个环节卡住、卡了多久。标准化后的写法记录了停留时长(45 秒)、操作轨迹(划过图标两次但没点)、最终行为(点了加购)、用户原话,分析时可以直接使用,不需要再回头翻视频。
三. 区分事实和解读
在整理笔记时,最容易犯的错误是把主持人的解读混进对事实的描述。
事实是可以被观察到的具体发生的事情;解读是对这件事情含义的判断。两者的区别看起来显而易见,但在快速记录的情况下,解读很容易不知不觉地混进去。
- 事实:"用户在支付页面点击了'取消'按钮"
- 解读(混进了事实):"用户不想付款,点击了'取消'"
"不想付款"是主持人对用户行为的推断,这个推断可能是对的,也可能是错的——用户可能是误触,可能是临时有事,可能是想先确认一下再回来付。把推断混进事实描述,后续分析时这条"事实"就带着一个预设立场,很难再中立地评估了。
整理笔记时的操作原则是:只写"看到了什么",不写"这意味着什么"。事实记在当下,解读留到分析阶段。这样整理出来的笔记是干净的原材料,分析时才能对着事实做判断,而不是对着已经带了解读的材料再加一层解读。
四. 亲和图
笔记标准化之后,接下来是把分散的观察,组织成可以看出规律的结构,亲和图(Affinity Diagram)是完成这件事最常用的方法。
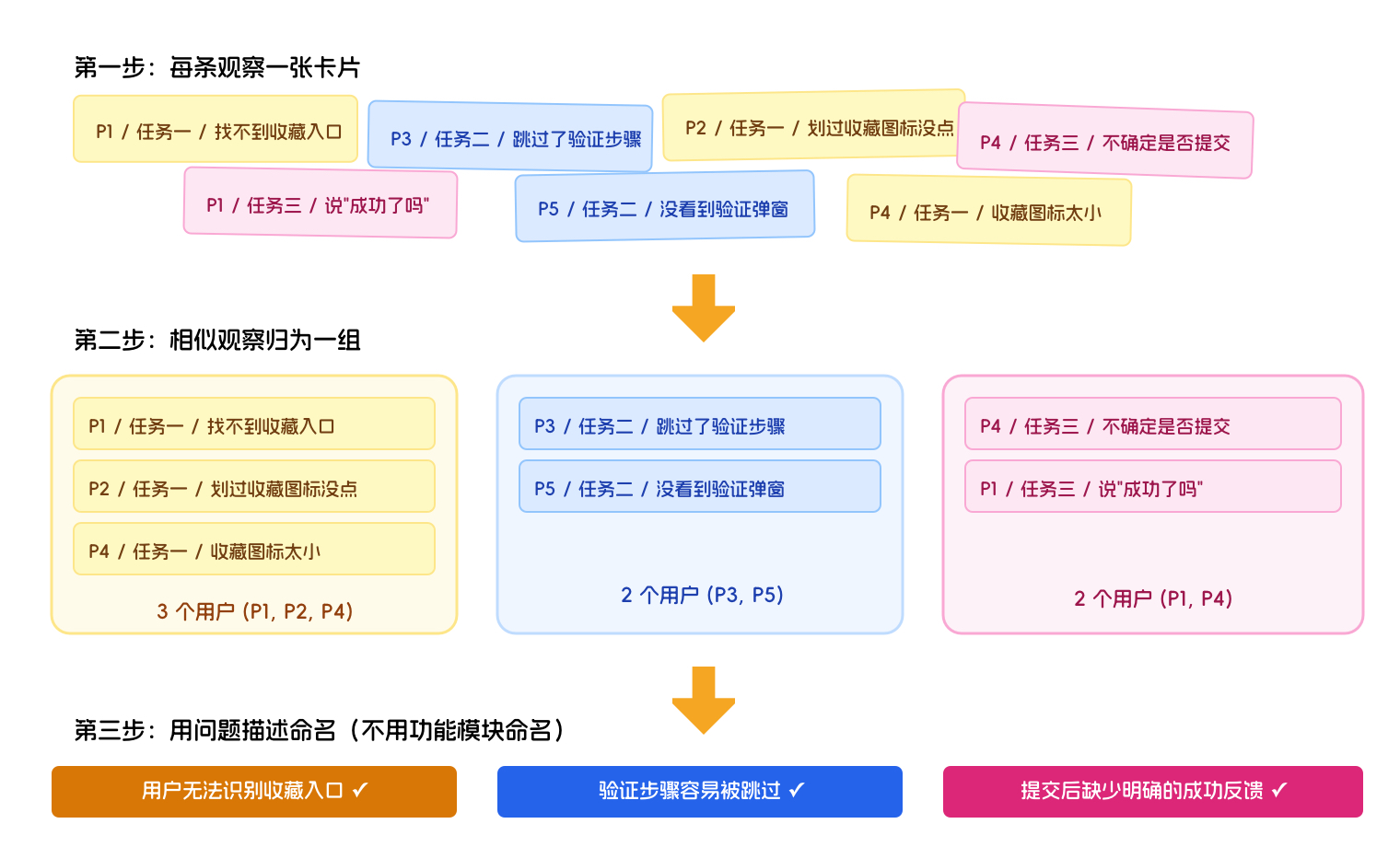
1. 操作步骤
第一步,把每条标准化的观察写在一张独立的卡片上。如果在数字工具里做,每条笔记对应一张便利贴;如果在线下做,就用真实的便利贴,一张一条,不要把多条观察写在同一张上,否则后续无法单独移动。
第二步,把所有卡片铺开,开始寻找相似的观察。什么叫"相似":描述同一类用户行为(比如多条笔记都在描述用户在某类操作上的犹豫);发生在同一个流程节点(比如多条笔记都来自任务一的第三步);涉及同一个界面元素(比如多条笔记都和导航栏的某个入口有关)。把相似的卡片移到一起,形成一个群组。
第三步,给每个群组命名。命名是亲和图里最重要的判断动作。命名要描述这组观察共同揭示的问题,而不是描述这些观察发生在哪个功能模块。
命名方式的对比:
- 功能模块命名(避免):"收藏相关问题"——这个名称说的是问题发生在哪里,但没有说明问题是什么。
- 问题描述命名(推荐):"用户无法识别收藏入口"——这个名称直接描述了这组观察揭示的核心问题。
问题描述命名的价值,在于它已经是一个初步的分析结论,后续写报告时可以直接使用;功能模块命名只是一个分类标签,还需要再做一层翻译才能变成结论。
第四步,检查群组的合理性。如果一个群组里的卡片太多,考虑能不能进一步细分;如果两个群组之间的差异很小,考虑合并。最终的群组数量没有固定要求,取决于数据本身的规律——通常在五到十五个之间是合理的范围。
2. 数字工具选项
亲和图可以在线上做,也可以在线下用真实便利贴做。线上工具(FigJam、Miro)的优势是多人可以同时操作,便利贴可以随意移动和重新分组,整理完的结果方便存档和分享。线下便利贴的优势是操作直觉感强,把卡片物理地移来移去,有时候更容易看出规律。两种方式效果相近,选自己和团队更习惯的那种。
五. 多场测试的数据如何合并
亲和图不是对每场测试的笔记单独做,而是把所有场次的观察放在一起做——这样才能看出哪些问题跨多个用户出现,哪些只是个例。
在整理时,每条卡片保留参与者编号(P1、P2、P3……)。一个群组里同时出现了 P1、P3、P4 的卡片,说明这个问题在三个用户身上出现了;只有 P2 的卡片出现在某个群组,说明这个问题可能是个例。这个频次信息是后续判断问题严重程度的基础数据,在整理阶段就需要保留好,不要在归组时把参与者编号丢掉。
六. 整理完之后应该能看到什么
亲和图做完,数据完成了从"原始笔记"到"结构化材料"的转变。这个阶段的终点不是"得出结论",而是"数据变得可比较了"。
整理完之后,应该能看到的是:哪些区域的卡片密度高(问题集中的地方),哪些问题有多个参与者的卡片(规律而不是个例),哪些问题只有一个参与者的卡片(个例,后续分析时需要区别对待)。
这些是进入分析阶段的起点,而不是分析的终点,用来判断严重程度、挖掘根因、提炼洞察,是我们下一篇内容要做的事。
有0人收藏了本文



















