
亲和图做完了,桌上有十几个问题群组,每个群组都有名字——"用户无法识别收藏入口""验证步骤容易被跳过""提交后缺少明确的成功反馈"。卡片里有来自不同用户的观察记录,哪些地方出了问题已经看得很清楚了。
但接下来的问题比较棘手:这十几个问题该先改哪个?收藏入口的问题和提交反馈的问题,哪个对用户的影响更大?"用户无法识别收藏入口"到底是因为图标太小、位置不对、还是图标本身看起来不像一个可点击的按钮?知道了"哪里有问题",距离知道"该怎么改"还有一段距离。
整理阶段把观察归了类,找出了问题在哪里。分析阶段要做的是下一步——判断每个问题的严重程度,挖出问题背后的原因,把"用户在这里卡住了"变成"这里需要改动什么"。
一. 观察和洞察的区别
分析阶段的核心工作是把观察转化成洞察。这两者的区别贯穿整个分析过程,需要先说清楚。
观察是测试中发生的事实。比如:三个用户在收藏这一步都花了超过三十秒,最终都没有找到收藏入口。观察回答的是"出了什么问题"。
洞察是从观察中提炼出来的、能指导设计改动的判断。比如:收藏图标没有文字标签,图标的颜色和周围的装饰性元素一致,用户无法从图标本身判断这是一个可点击的功能入口。洞察回答的是"为什么出了这个问题",并且指向"应该改什么"。
两者的区别决定了报告的实用性。如果报告里只写观察——"三个用户找不到收藏入口"——产品团队知道了有问题,但不知道该怎么改。如果报告里写到了洞察——"收藏图标缺少文字标签,视觉权重不足,用户把它当成了装饰",那么设计师可以直接把这条结论转化成一个设计任务:给图标加文字标签,调整图标的颜色对比度。
二. 问题严重程度分级
拿到亲和图之后,第一步不是挖根因,而是判断每个问题的严重程度。不可能所有问题都在下一个版本里改完,产品团队需要知道应该先改哪些。

问题严重程度:频率 × 影响
评估严重程度看两个维度:发生频率(几个用户遇到了这个问题)和影响程度(这个问题对用户完成任务的阻碍有多大)。两个维度综合判断,分成三个级别:
1. 严重
用户无法独立完成任务,最终需要主持人介入或者放弃任务。判断的依据是行为结果——任务是否完成——而不是主持人的主观感觉。如果两个以上的用户在同一个任务上失败,这个问题通常属于严重级别。有些问题即使只出现在一个用户身上,但性质是任务完全失败,在真实使用场景中意味着用户直接流失,也应该列为严重。
2. 中等
用户最终完成了任务,但过程中遇到了明显的困难——停顿超过三十秒、走了错误路径又折返、误操作之后才纠正过来、口头表达了明确的困惑。任务完成了,但完成得不顺畅。
3. 轻微
用户有短暂的停顿或疑惑,但迅速自行解决了,整体流程没有受到明显影响。停顿时间很短,没有误操作,用户可能说了一句疑问但随即消除了。
需要注意的是:严重程度的依据是用户的行为数据(任务是否完成、花了多长时间、走了多少错误路径),不是主持人在现场的感受。"我觉得用户当时看起来有点困惑"不能作为判断严重程度的依据,"用户在这个页面停了 45 秒,点了三个错误的入口,最终放弃了任务"才是。
三. 区分规律和个例
亲和图里的每个问题群组,都需要判断它反映的是规律还是个例。
规律:两个或两个以上的用户在同一个地方遇到了类似的问题。这类问题反映的是产品本身的可用性缺陷,不是某个用户的特殊习惯或某次测试的偶发状况。规律性问题是报告的核心内容,优先处理。
个例:只有一个用户出现的问题。个例不能直接当作结论,因为有可能是这个用户的特殊背景导致的,也可能是当次测试的偶发情况。个例不要丢弃,在报告里记录下来,注明"仅一位参与者出现,需在后续测试中观察是否重复"。
有一种情况需要单独对待:只有一个用户出现,但这个用户完全无法完成任务。频次虽低,影响程度却很高,在真实使用场景中,这意味着这类用户会直接流失。这类个例应该在报告里单独提出,说明频次低但风险高,建议在下一轮测试里重点关注。
四. 从现象挖到根因
严重程度定下来之后,对每个中等和严重级别的问题,需要进一步挖根因——找到导致这个问题的具体设计原因。
挖根因的方法是逐层追问"为什么",每次追问一层,直到追到一个可以直接改动的设计决定为止。"用户体验不好"不是根因,因为设计师拿到这句话不知道该改什么;"按钮缺少文字标签"是根因,因为设计师可以直接执行"加上文字标签"这个改动。
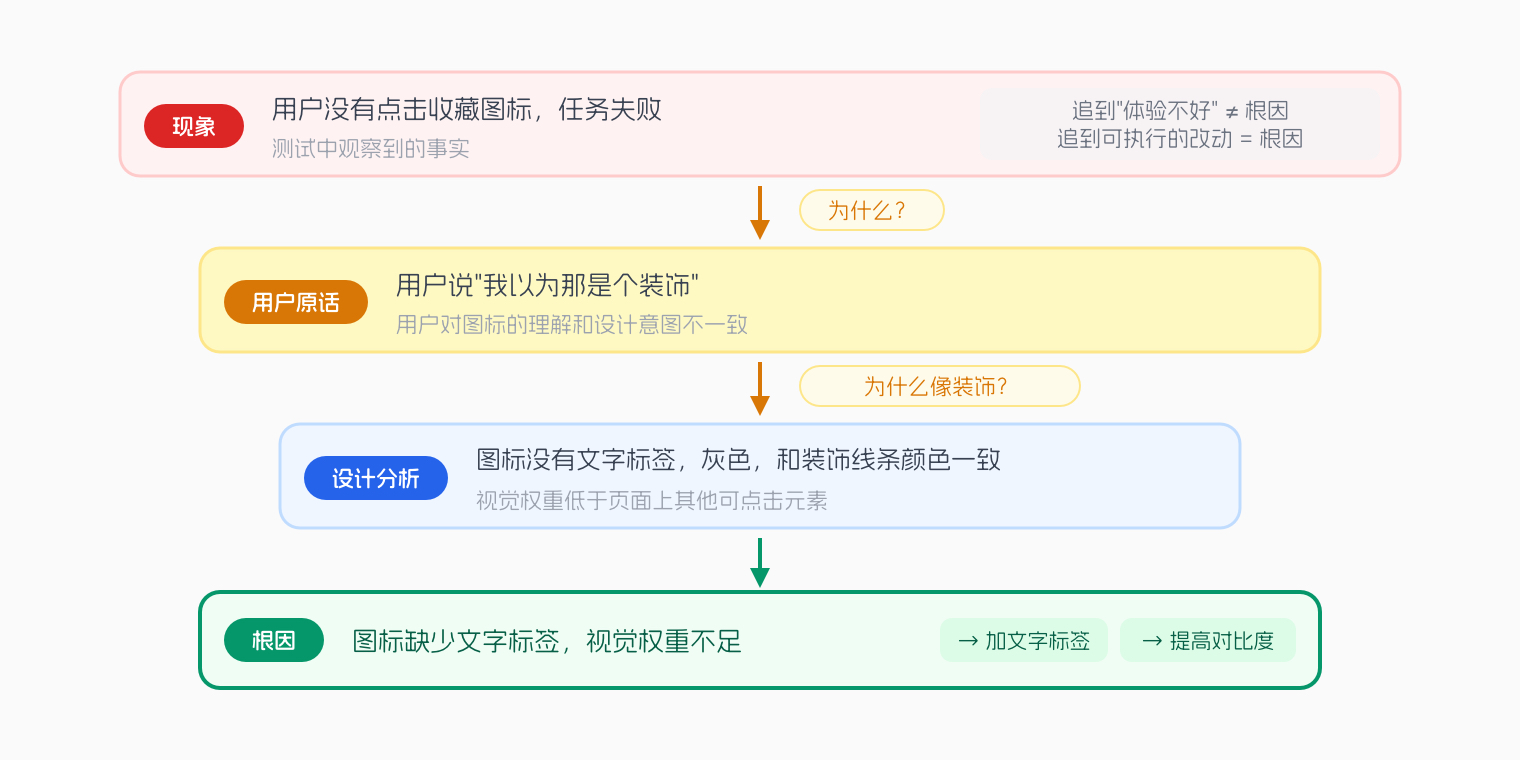
逐层追问"为什么":从现象到根因
一个完整的追问过程:
- 现象:用户没有点击收藏图标,任务失败
- 为什么没点?用户说"我以为那是个装饰"
- 为什么图标看起来像装饰?图标没有文字标签,颜色是灰色,和周围的装饰性线条颜色一致,视觉权重低于页面上其他可点击元素
- 根因:图标缺少文字标签,视觉权重不足,用户无法识别这是一个功能入口
这个根因直接指向两个设计改动:增加文字标签,提高图标的视觉权重(改变颜色或增加对比度)。设计师拿到这条结论就可以直接动手,不需要再做额外的翻译。
根因不一定都在视觉细节层面,有时候指向的是更深层的结构问题:
- 用户完成了任务,但走了一条绕路——用户按自己的逻辑在找路,和产品的信息架构组织方式不一致,流程结构需要调整
- 多个用户在同一个位置犹豫,朝不同方向探索——这个位置的视觉层级混乱,没有给用户提供清晰的下一步指引
- 用户完成任务后反复确认操作是否生效——关键操作之后缺少明确的反馈,用户不确定自己的动作有没有成功
这类根因指向的改动范围更大,可能需要调整信息架构、重新设计关键流程,不是改一个按钮就能解决的。在报告里需要写清楚改动的范围和复杂度,让产品团队知道这不是小改,需要相应的资源和时间投入。
五. 确认偏误的陷阱
分析阶段有一个常见的陷阱:设计师在不自觉地偏向对自己有利的结论。
这种偏向叫确认偏误——人在处理信息时,倾向于关注支持自己已有判断的数据,对不支持的数据选择性地忽略或淡化。在可用性测试分析中,确认偏误的表现是:设计师对自己做的设计有预期("这个流程应该没问题"),分析时会不自觉地放大"用户顺利完成了"这条数据,弱化"但用户中途绕路了三次"这条数据,最终得出比实际情况更乐观的结论。
减少确认偏误最有效的办法是在分析过程中引入另一个人——产品经理、另一位设计师或用研同事。没有参与设计的人看同一份数据,更容易注意到被忽视的问题,也更容易对"这应该只是偶然"的判断提出质疑。具体做法是:两个人各自对同一份亲和图独立做一轮初步判断(严重程度、根因),然后对比两人的差异,讨论分歧点。这样做能有效减少一个人独自分析时的盲区。
另一个办法是在上一篇介绍的整理阶段就严格区分事实和解读。如果整理出来的笔记是干净的事实("用户点了取消按钮"),分析时对着事实做判断,得出偏颇结论的空间会小很多。如果笔记里混进了解读("用户不想付款,点了取消"),分析时就是在解读的基础上再做一层解读,偏差会叠加放大。
有0人收藏了本文



















