
可用性测试分析做完了,设计师花了三天写了一份测试报告:18 条可用性问题,每条都配了截图、问题描述和根因分析。然后她报告发给产品经理,邮件标题写的是"上周可用性测试发现,请查阅"。产品经理回了两个字:"收到。" 但两个月后,18 条问题一条都没改。
要知道这并不是产品经理不重视可用性测试,而是他压根不知道该从哪条问题开始。报告里的 18 条问题,没有标注哪些最紧急,没有说先改哪个,也没有提到改一个大概要投入多少开发资源。他读完报告知道"产品有18 个可用性问题",但下一步该做什么,报告并没有告诉他。
所以,即便报告写得再完整,如果不能帮读者做出"先改哪个"的决定,就推不动不了任何改动。
一. 报告要服务于受众
报告的目的不是展示测试做了多少工作,而是能让特定的受众采取特定的行动。不同受众关注的问题不同,写报告之前需要先想清楚谁会读它、读完之后需要做什么。
- 设计团队需要知道:具体是哪里出了问题,根因是什么,有什么设计建议可以直接执行。设计师关心的是改什么、怎么改。
- 产品经理需要知道:哪些问题影响了产品的核心业务目标,优先级怎么排,改动大概需要多大的资源投入。产品经理关心的是先改哪几个、为什么先改这几个。
- 高层或利益相关方需要知道:测试的总体结论是什么,最重要的几个发现是哪些,对产品有什么影响。高层通常没有时间读细节,需要的是一页纸就能看完的摘要。
当然,实际情况是不需要写 3 份完全不同的报告。一份完整报告搭配一份管理层摘要就够了:完整报告包含所有细节,面向设计和产品团队;管理层摘要只有一页,写最重要的三到五条发现和对应的建议,不含细节,供需要快速了解结论的人使用。
二. 报告的基本结构
1. 测试背景
报告的开头,用半页以内的篇幅交代这次测试的来龙去脉:测试了什么产品、招募了几个什么样的用户、测了哪些任务、目的是回答什么问题。
这部分面向的是没有参与过测试的读者。读者在看到发现之前,需要先知道这些结论是怎么来的——用了几个用户、测的是什么阶段的产品、测了哪些核心流程。没有背景信息,读者无法判断结论的可信度,也无法判断结论是否和自己关心的问题相关。
2. 关键发现
关键发现是报告的核心,通常占最大篇幅。按严重程度排序:严重问题排在最前面,确保读者第一眼看到的是最需要处理的问题。
每条发现用统一的结构来写:
- 问题描述(一到两句):说清楚这是什么问题,发生在产品的哪个环节。
- 证据:支持这条发现的数据——几个用户遇到了这个问题,用户的操作行为是什么,有没有可以直接引用的用户原话,截图或视频片段的位置。
- 根因:这个问题为什么会发生,指向哪个具体的设计决定。
- 出现频率:五个用户里有几个出现了这个问题。
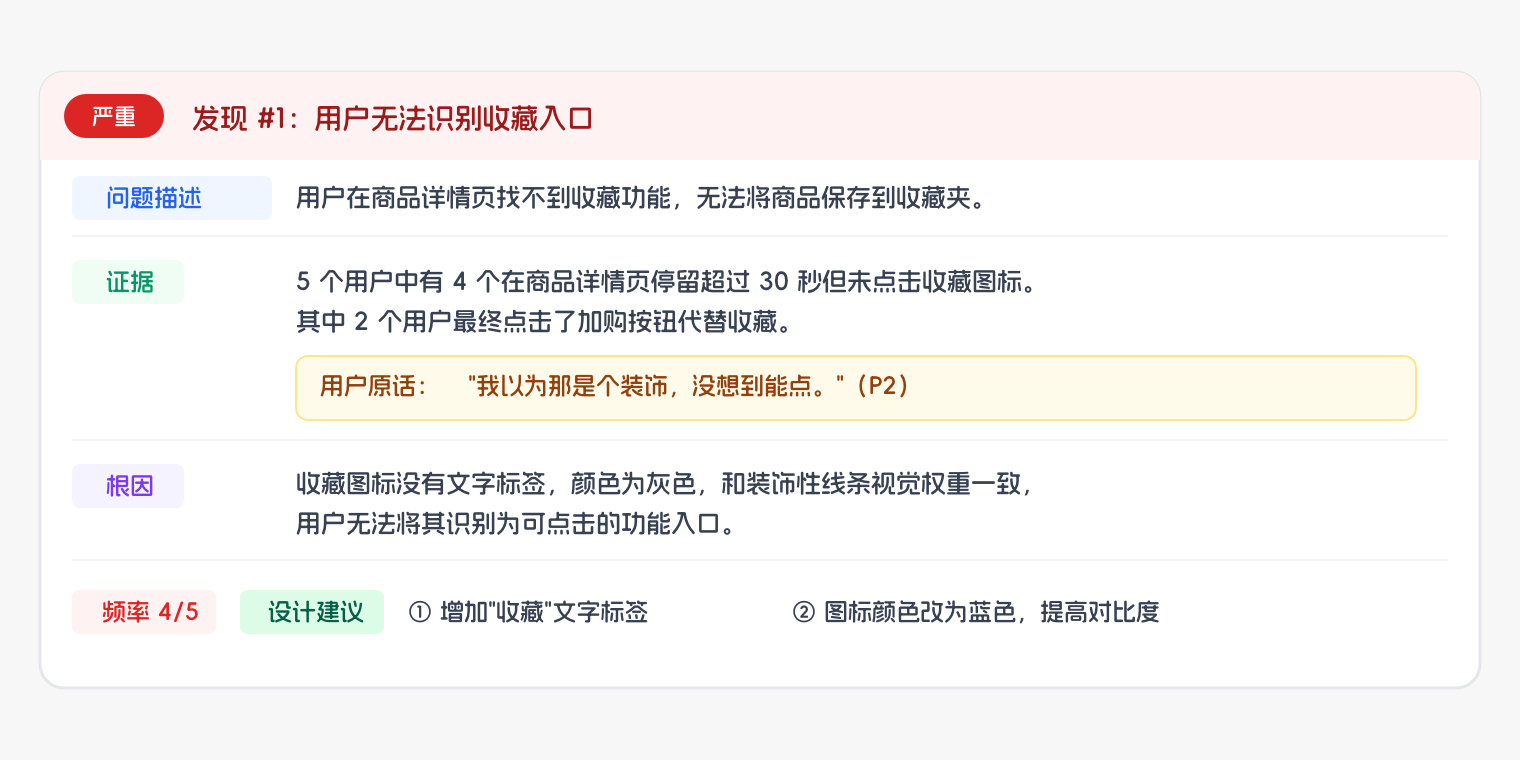
每条发现的写法结构(示例)
证据是报告说服力的来源。"用户找不到收藏功能"是一句陈述,读者可以质疑"也许只是这个用户不够仔细"。"五个用户中有四个在商品详情页停留超过 30 秒,但没有点击收藏图标,其中两个用户说'我以为那是个装饰'"——这是有数据和用户原话支撑的证据,读者很难用"个别用户的问题"来解释四个人的一致行为。
3.设计建议
设计建议可以紧跟在每条发现之后,也可以单独成章,取决于报告的格式偏好。
建议必须写到具体可执行的程度,不能只给方向。
- 方向性建议(不够用):"改善收藏功能的可发现性。"产品经理和开发看到这句话,不知道具体要做什么。
- 可执行建议:"在收藏图标旁边增加'收藏'文字标签;将图标颜色从灰色改为与主操作一致的蓝色,提高视觉权重,让用户能识别这是一个可点击的功能入口。"设计师拿到这条建议可以直接动手,产品经理可以直接评估工作量。
4. 优先级排序
所有发现列出来之后,需要给出优先级排序,告诉产品团队先改哪些。如果把 18 条问题等长地列出来、不做排序,产品团队面对的是一张清单,每条看起来同样重要,结果是哪条都没有被优先处理。
优先级的排序框架:严重程度 × 修改成本。
- 严重 + 修改成本低:立刻修,不需要等下个大版本
- 严重 + 修改成本高:列入近期版本计划,需要资源投入
- 轻微 + 修改成本低:顺手改,开发有空时处理
- 轻微 + 修改成本高:暂时搁置,下一个大版本统一考虑
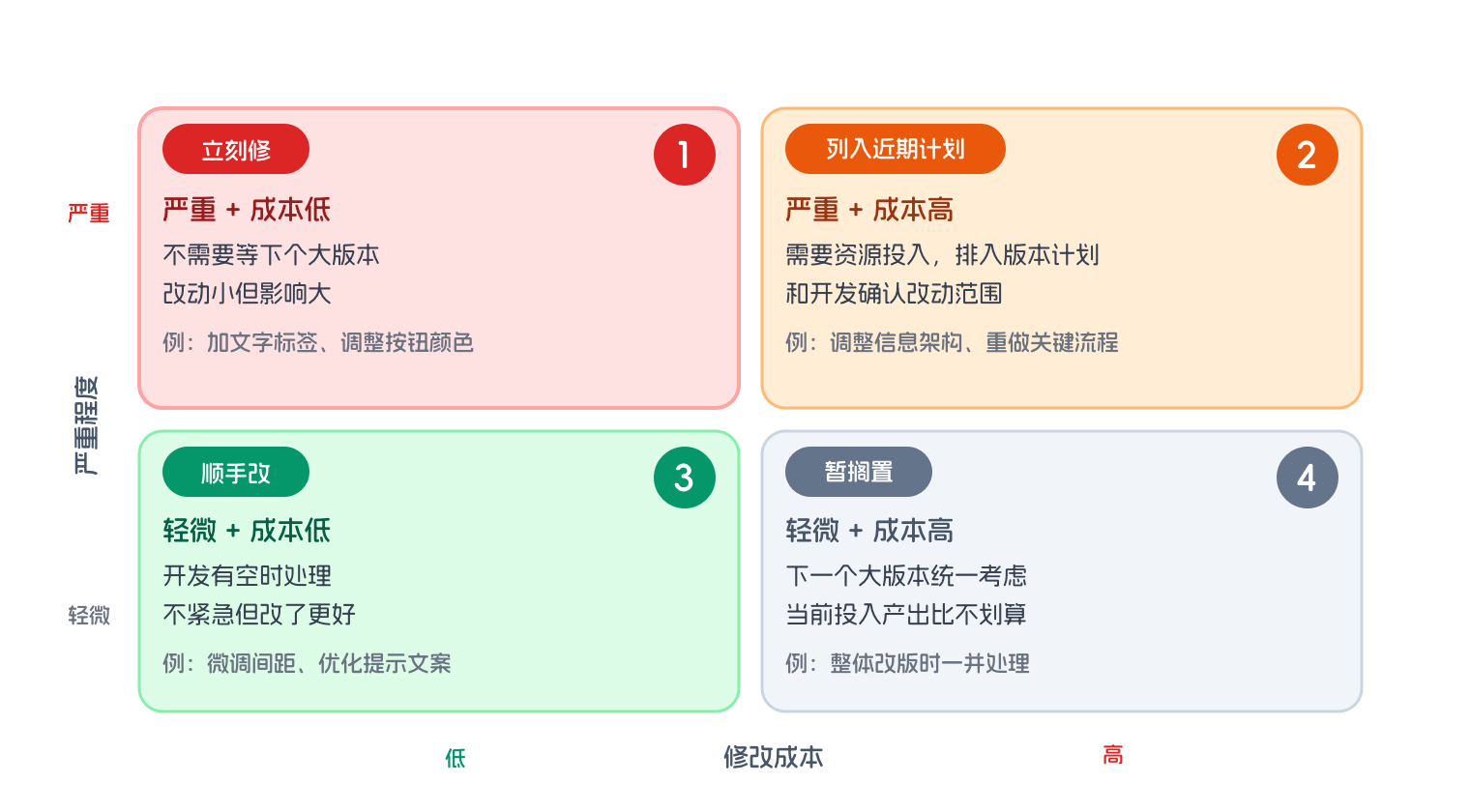
优先级排序:严重程度 × 修改成本
修改成本不是设计师单独能判断的,需要和开发沟通。有些问题看起来只是改一个颜色,背后可能涉及组件库的修改,改动范围比表面看到的大。在排优先级之前,和开发快速对一下每条建议的改动范围,能让排序更准确,也能提高建议被采纳的可能性。
三. 让发现有说服力
报告里的证据有三种形式,按说服力从高到低排列:用户原话、视频片段、设计师的概括描述。
用户原话的说服力最强,因为它带着真实的情绪和具体性。"用户在收藏功能上遇到了困难"是设计师的概括,读者可以质疑"也许只是这个用户不熟悉"。而"用户说'我以为那是个装饰,没想到能点'"是一个真实用户的真实感受,读者很难否认这个人确实是这么想的。在整理笔记阶段保留下来的用户原话,在报告里可以直接引用,不需要改写——改写往往会削弱原话的力量。
视频片段比文字描述更有冲击力。一段 30 到 60 秒的视频,显示用户在收藏页面反复尝试、最终放弃,比任何文字描述都更能让读者感受到问题的真实程度。如果时间允许,在报告发出之前剪出两三个关键片段,对应最重要的几个问题。不需要很多,两三个最能说明问题的场景就够了。
四. 如何在团队会议里呈现
发报告不等于呈现发现。报告是参考材料,会议才是让关键人员理解发现、做出决定的场合。
会议的节奏建议如下:

- 先用三到五分钟交代测试背景——测了什么,几个用户,什么任务。这部分不需要详细,只需要让没看过报告的人知道数据从哪来。
- 然后直接播放视频片段。不要一上来就讲结论,先让所有人看到用户卡住的过程。看完之后,在场的人都有了同样的第一手感受——他们不是在听设计师转述"用户遇到了问题",而是亲眼看到了用户在屏幕上来回找、最终放弃的过程。这种直观感受是文字无法替代的,也是后续讨论设计建议时大家能达成共识的基础。
- 视频看完之后,呈现优先级排序,引导讨论:这几个问题下一步怎么处理?哪些在下个版本里改,哪些先搁置?每条由谁跟进?
会议的目标是做出决定,不是汇报工作。结束时每条重要发现都应该有明确的负责人和时间节点,而不只是"大家都知道了"。
五. 测试结束不是终点
可用性测试的价值,最终取决于它推动了什么改动,以及这些改动是否解决了测试发现的问题。
每条设计建议需要进入团队的迭代计划,变成有人跟进的设计任务。如果建议停留在报告里,没有对应的后续行动,测试的价值就没有被兑现。
改动上线之后,应该针对改动过的地方再做一次简短的验证——三到五个用户,只测改动涉及的任务,确认问题是否已经解决。这不需要完整的新一轮测试,几个小时就能完成,但它能确认设计改动确实生效了,而不是改完之后没人知道结果。
从更长的时间跨度看,可用性测试应该成为设计流程里的常规动作,而不是偶尔做一次的大项目。每个版本上线前做一轮、上线后做一轮,形成持续的迭代反馈。在这样的节奏下,每次测试的规模可以更小(三个用户、一两个核心任务),但持续积累下来对产品可用性的提升,远比每年做一次大规模测试更有效。
有0人收藏了本文



















