
我把用户画像打印出来贴在会议室白板上时,觉得这个工作做完了。两天的工作量,有照片、有名字、有代表性引言,痛点和目标列得整整齐齐。汇报那天产品经理也说"做得很好"。
三个月后,画像还在白板上,纸边已经微微卷起来。这三个月里团队做了两次迭代,开了十几场评审,没有一次有人在讨论中提到过它。不是大家忘了,是从一开始就没有人知道该怎么用它。
那份画像的问题不在格式,在于它从来没有建立在真实数据上。我填进去的那些内容,不是从真实用户身上观察到的,而是对"我们的用户大概是什么样子"的想象。这种想象做出来的东西,外表和真实画像几乎一样,但内核是空的。
一、用户画像究竟是什么
用户画像(User Persona)这个词在设计行业已经快被说烂了,但很多团队在真正做画像的时候,还是会习惯性把它做成一个视觉好看的"用户介绍卡片",而不是一个对设计决策真正有作用的工具。
要理解画像是什么,就要先理解它解决的是什么问题。
设计团队在工作中会反复会遇上这样一个问题,那就是我们到底在为谁设计?这听起来并不复杂,但团队里每个人的脑子里的答案其实完全不一样。设计师想的是"使用产品的年轻白领",产品经理想的是"能付费的城市用户",老板想的是"我们的目标客群是25到40岁的中产消费者"。
结果就是,开评审会时,大家讨论的是同一个设计方案,但心里参照的是不同的用户。有人觉得这个功能对用户有用,有人觉得用户不需要这个,争来争去,谁也说服不了谁。因为每个人所说的"用户"根本不是同一个人。
用户画像要解决的,就是这个问题。
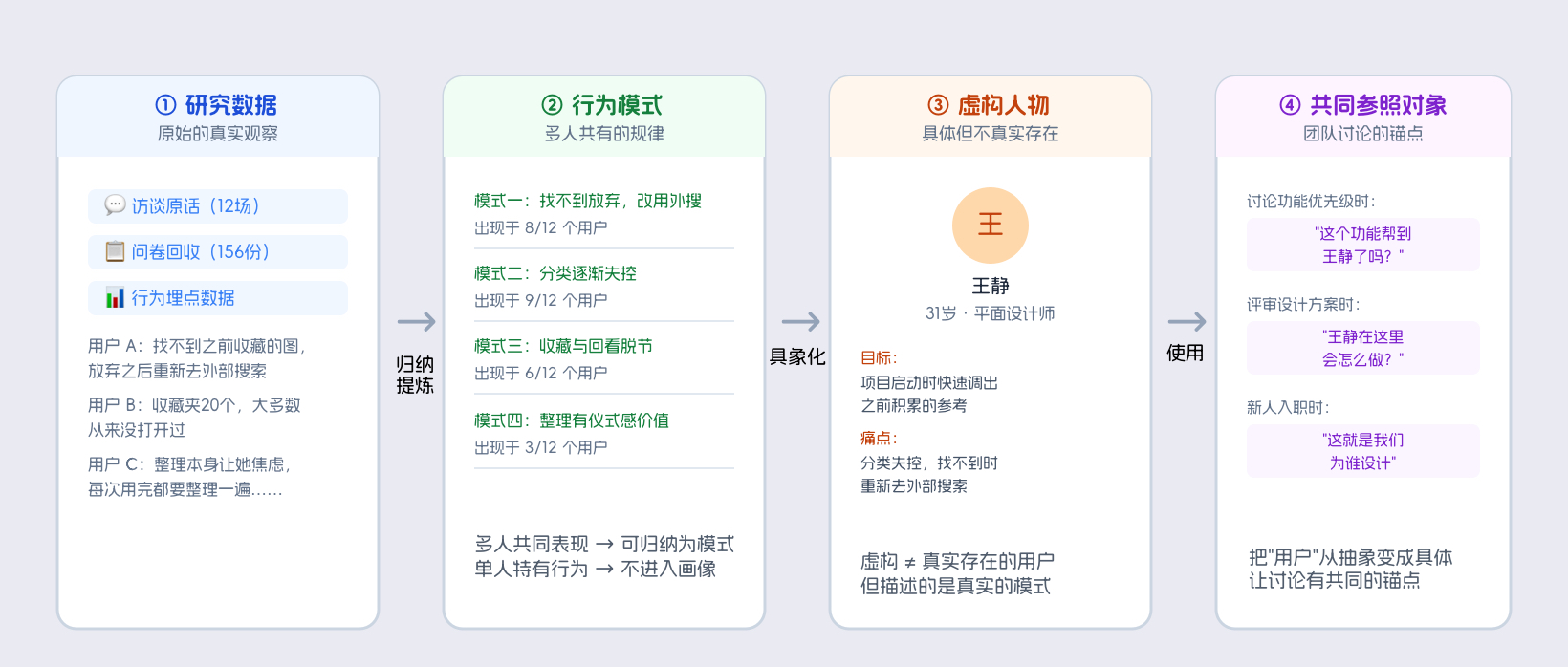
用户画像是对研究数据的提炼。它把在真实用户身上观察到的行为模式、共同痛点、使用习惯,压缩成一个具体的虚构人物,让团队在设计讨论时有一个共同的参照对象。
注意这里面有三个关键词:
第一,"研究数据的提炼"指的是画像不是凭空创造的,而是从真实的研究数据里提炼出来的。没有研究数据,就不存在真实的画像,有的只是团队的集体想象。
第二,"行为模式的归纳"指的是画像描述的是一类人共同表现出来的模式,不是某一个特定用户的具体情况。研究过程中如果发现了五个人都有相似的操作习惯,这个习惯就可能成为画像的一部分;但如果只有一个人有某种特殊行为,它通常不应该进入画像。

第三,"共同的参照对象"指的是画像最终的用途,是让整个团队在讨论"用户"时,脑子里浮现的是同一个人。有了这个具体的人,团队讨论就从"用户会不会觉得……"变成"王静在这种情况下会怎么做"。这个替换很微妙,它改变了讨论的质量,从大家各自猜测一个抽象群体,变成对照一个有数据支撑的具体人来做分析。

二、画像让设计决策变容易
理解了画像的定义,再来看它在实际工作中的用途。一个有数据支撑的真实画像,至少在三类决策场景里能帮上忙。
1. 功能优先级讨论
产品路线图上有十几个功能等着排期,团队要决定先做哪个。没有画像的时候,每个人按自己的判断排优先级,讨论很容易变成观点对观点。有了具体的画像,问题就变成了:哪些功能直接对应王静的核心行为和核心痛点?画像不会替团队做决定,但它把争论的出发点从"我们各自觉得哪个重要"换成了"对这类用户哪个更重要",让讨论有了一个共同的锚定点。
2. 设计方案的取舍
假设设计评审中有两个方案,A方案功能更全,B方案流程更简单。怎么选?如果没有画像,这通常变成一场口水仗。如果有画像,可以问:她是坐在办公桌前完整地用,还是通勤路上抽几分钟用?她每天会打开这个功能几次?这些具体的信息能帮助团队把抽象的"简单"和"全面"之争,落到"对这个用户来说哪个方案更合适"的讨论上。
3. 新成员的认知对齐
产品团队里经常有新人加入,每次让新人从零开始理解"我们的用户是谁"都要花很多时间。一份详实的画像,能让新成员在第一周就建立起对目标用户的基本认知,知道这类用户的行为习惯、核心诉求、使用场景,而不是在入职一个月后还对用户一无所知。
这三个用途都有一个共同前提:画像描述的内容必须来自真实观察,而不是团队的假设。一旦画像建立在假设上,这三类讨论就都失去了意义。
三、假画像是怎么来的
既然画像必须来自真实研究,为什么很多团队做的其实是假画像?
因为做出一份看起来像样的画像,比真正基于数据做画像容易得多。一个有名字、有照片、有整齐字段的文档,外表和真实画像几乎一样。没有亲自参与研究的人,很难从外表上分辨真假。
假画像通常来自三种情境:
1. 凭空捏造型
凭空捏造型是最常见的一种。团队没有做过用户研究,或者只做过非常有限的研究(比如做了两三次访谈,每次只聊了二十分钟),没有足够的数据支撑一份完整的画像。但项目需要推进,或者老板要求"做一份用户画像",于是团队就开始填格子:
- 用户是谁?"25到35岁的城市职场女性"。
- 核心痛点是什么?"工作和生活的平衡很难把握,需要高效的工具来管理时间"。
这些内容不是从研究中观察到的,而是大家集体想象出来的,或者从竞品的目标用户描述里借来的。
这类画像读起来感觉合理,因为它描述的就是团队自己认为"应该是这样"的用户。团队不会主动质疑自己写的东西,自然觉得对。问题是没有人能看出哪里错了,但每一个设计决策都在参照一个错误的用户模型,偏差会随着产品迭代越来越大。

2. 平均人型
平均人型来自一种看似严谨的做法。团队做了调研,收集了几十上百份问卷,然后把所有人的特征取平均值,得到一个综合画像。25到35岁,有一定受教育程度,对价格有一定敏感性,希望产品高效易用。单独看每一条都没错,但放在一起,这个人在现实里不存在。
真实用户之间的差异是有意义的。有的用户用产品是为了工作效率,有的是为了娱乐消遣。有的是重度用户每天打开,有的偶尔才用一次。有的愿意花时间学复杂功能,有的只想要最简单的操作。这些差异往往指向完全不同的设计方向。把所有人取平均值,就把这些差异全部抹掉了,剩下一个对所有人来说都"差不多合适"的幽灵用户。用这个画像做设计,等于在为一个不存在的人设计,团队没办法从中做出任何有区分度的判断。

3. 老板驱动型
老板驱动型和前两种不同,研究是真做了的,访谈做了,数据也收集了。问题出在整理数据、提炼洞察的环节。研究发现的真实结论和产品现有定位或老板的预期不符,画像的内容就被有意无意地"调整"了,朝着符合期望的方向靠拢。
这类情况很常见,往往不是研究者故意作假,而是一种自我审查:这个发现太麻烦了,写进去会引起争议;那个结论老板肯定不喜欢,就不写了;这部分观察和我们的产品方向不符,就弱化处理吧。最终呈现出来的画像,有真实研究的外壳,但结论已经被过滤过了,核心问题被绕开了。这种画像比凭空捏造型更难被识别,因为说"这是我们做了研究之后得出的",没有人会去追问研究结论是否被完整呈现。

四、真假画像的差距在哪里
从外面看,真实画像和假画像差距不大。格式相同,字段相同,视觉呈现也相似。真正的差距藏在每个字段的具体程度里。
拿"痛点"这个字段来举例,同样是描述一个内容整理类产品的目标用户的痛点,假画像通常是这样写的:
- 希望内容整理更方便,收藏管理不够清晰,在找资料时经常感到效率低下。

真实画像是这样写的:
- 存了很多参考图,但分类一直乱,找东西要翻好几个文件夹,经常找不到,最后直接放弃重新搜。工作用的和生活用的内容混在一起,不同项目的参考图没有办法区分。上周项目启动,花了将近半小时找上个季度存的竞品截图,最后没找到,当场去重新截图。平均每次找一个之前存的东西要花七八分钟。

这两段文字的差距不是文字多少的差距,是背后有没有真实观察的差距。
第一段描述的是一个设计方向:任何收藏类产品的用户都可以贴上这个标签,它对任何设计决策都没有实质帮助。没法从它推断出应该优先设计标签功能还是搜索功能,没法推断用户会不会愿意花时间整理分类,没法推断操作路径应该是深层还是扁平。
第二段描述的是一个具体的行为场景:这个用户存了大量内容但缺乏清晰的分组逻辑;不同来源和不同用途的内容被混放;主要的痛点不是"收藏不够多",而是"找不到之前收藏的东西";她的解决方式是放弃找,重新搜索,说明搜索能力对她来说是关键的逃生路径;"半小时找截图"这个故事说明问题已经到了影响工作的程度。
从这段描述,设计团队可以推断出很多有用的信息:
- 搜索功能的优先级应该很高
- 打标签这种需要主动维护的方案
- 这类用户可能没有动力坚持
- 帮助用户在导入时自动归类比让用户手动分类更可能被接受;
- ...
这就是真画像和假画像的差距。真实的观察能支撑设计推断,泛泛的描述什么也推不出来。
除了痛点,其他字段也是一样的逻辑。目标字段如果写"希望工作更高效",这是假画像的水平;如果写"每周的周报要花两个多小时整理,她觉得这时间浪费在形式上,想控制在45分钟以内",这才是真实画像该有的内容。行为习惯字段如果写"经常使用手机处理工作",这是假画像;如果写"通勤时用手机处理非紧急任务,下班后不打开工作软件,周末基本不用",这才能指导设计决策。
五、识别真假画像
拿起画像,随机挑一个字段,问一个问题:这句话是从哪个用户访谈或研究数据里得出来的?
如果有人能回答出"这是从第三次访谈的第二个受访者那里观察到的,后来在问卷里也有32%的用户提到了类似情况",这是真实画像。
如果没有人能回答,或者回答是"这是大家讨论之后觉得应该是这样的",这是假画像。
第二个判断方式是看字段的具体程度。真实画像的每个字段都应该能直接指导一个设计决策。如果一个字段读完,团队对"应该怎么设计"没有任何新的判断,这个字段大概率是假的,它描述的可能是一个普遍正确但对这个产品没有特殊意义的特征。
第三个判断方式是看字段之间是否自洽。真实用户的行为、痛点、目标、背景是相互关联的,一份可信的画像读起来会觉得"这些放在一起,确实像一个真实的人"。假画像的字段通常是独立填写的,放在一起会出现矛盾。比如痛点写着"时间很紧张",行为习惯里却描述了大量主动探索新功能的行为,这两件事放在同一个人身上就对不上。
六、画像能做什么,做不到什么
学会一个工具之后容易把它用在所有问题上,所以最后要说清楚画像的边界。
1. 画像能做的事
画像最核心的价值是给团队一个共同的用户讨论对象,让"用户"从一个抽象的群体概念变成一个具体的人。当团队讨论功能优先级或方案取舍时,画像提供了一个参照坐标,把"我们觉得"的判断变成"对这类用户来说"的判断。对新加入的成员,画像也能帮他们快速建立对目标用户的基本认知,缩短上手时间。
2. 画像做不到的事
画像不能预测用户行为。它是对已有行为模式的归纳,不是对未来行为的预测。"王静之前是这样做的",不等于"王静遇到新功能时也会这样做"。在验证一个未经测试的新设计方案时,不能用画像替代真实的可用性测试。
画像不能覆盖所有用户。一两个画像只能代表最主要的用户群体,描述的是这类用户中最典型的行为模式。边缘用户、特殊使用场景、极端情况都不在其中。一个面向主流用户的好设计,同时可能对某些特殊需求的用户体验很差——这不是画像的错,是它的边界。
画像不能替代持续的用户研究。画像是某个时间点的快照,描述的是"在做这份研究的那段时间里,这类用户大致是这样的"。用户在变,产品在变,市场在变,三个月前的画像可能已经部分失效。画像需要定期用新的研究数据来校准,否则会变成一个把团队锚定在过时认知上的绊脚石,而不是帮助工具。
有0人收藏了本文



















