
同样是测试"用户能不能完成购买流程",两种任务描述方式会带来完全不同的测试结果:
- 版本 A:"请点击页面右上角的购物车图标,然后完成结账流程。"
- 版本 B:"你刚才浏览了一件喜欢的外套,现在想把它买下来。"
版本 A 在任务描述里告诉了用户答案——购物车在右上角,用户看到任务就知道第一步该做什么。这不是在测试用户能不能找到购买入口,而是在告诉用户入口在哪里然后让他们点过去。测试的核心信息被任务本身提前消除了。
版本 B 给了用户一个场景和目标。用户要自己决定从哪里开始,要自己找到购买路径。主持人能观察到用户的第一反应是什么,视线停在哪里,第一步点了哪里,走了几步才到达结账——这些才是测试想要收集的行为数据。
一. 好的测试任务的三个特征
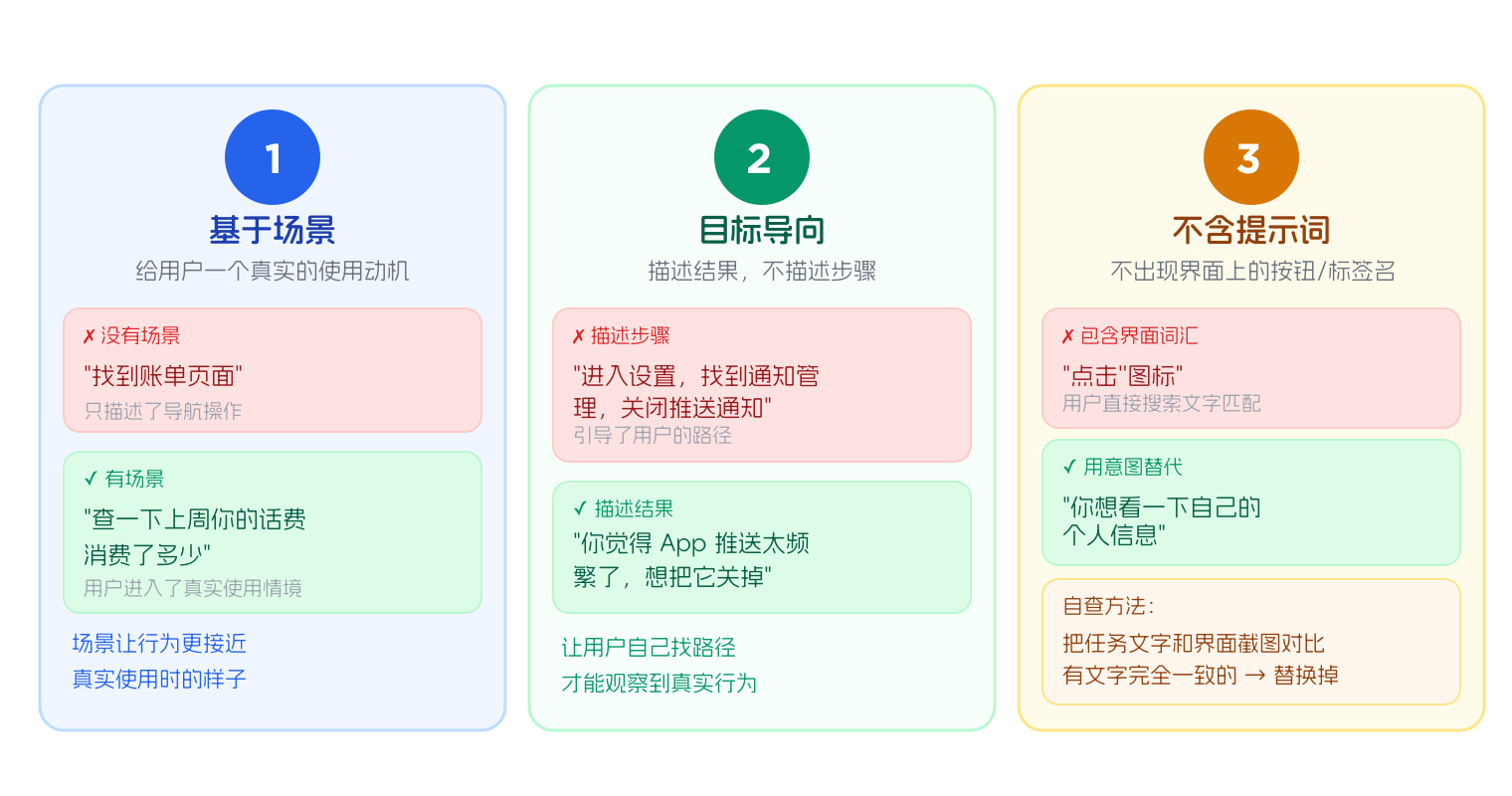
1. 基于场景
好的测试任务设定,会给用户一个真实的使用动机,让他们知道自己为什么要完成这个操作,而不是直接告诉他们要完成什么操作。场景让任务有了背景,用户的行为会更接近真实使用时的样子。"查一下上周你的话费消费了多少"比"找到账单页面"更有场景感——前者让用户进入了一个真实的使用情境,后者只是在描述一个导航操作。
2. 目标导向
写测试任务时只需要告诉用户想要什么结果,不要把操作步骤写进去。比如同样是测试"用户能不能关闭推送通知","进入设置,找到通知管理,关闭推送通知"把每一步都写出来了,用户照着走就行,测试观察不到用户自己会怎么找。而"你觉得 App 推送太频繁了,想把它关掉"只告诉用户想要的结果,用户需要自己决定从哪里入手、走哪条路径——这些自主决策的过程,才是测试要观察的行为。
3. 不包含界面提示词
界面上出现的按钮名称、菜单标签、图标描述,不能出现在任务里。这些词是线索,用户看到任务里有"点击'我的'图标",就知道要去找标着"我的"的地方。测试想观察的,恰恰是用户在没有这些提示的情况下能不能找到正确的入口。检查任务的方法很简单:把任务文字和界面截图放在一起,看任务里有没有词语和界面上的元素文字完全一致,如果有的话,替换掉。
好的测试任务的三个特征
二. 如何把测试目标转化成测试任务
每个测试目标对应一到两个核心任务,转化步骤是固定的:
第一步,写出这个目标对应的真实使用场景——用户在什么时候、因为什么原因、想完成什么事。这是场景构建,越具体越好。
第二步,把场景提炼成一段简短的任务背景说明,去掉多余的细节,保留动机和结果目标。长度通常在两三句话以内——太长用户记不住,太短没有足够的场景感。
第三步,检查任务里有没有界面提示词,有则替换成描述用户意图的表达。
第四步,想清楚"任务完成"的判断标准:用户到了什么状态,主持人认为这个任务结束了。这个判断标准需要在测试前想好,否则测试过程中主持人会不知道什么时候该结束任务、开始追问。
一次测试的任务数量保持在三到六个之间。任务太少,不足以覆盖测试目标;任务太多,测试时间拉长,用户在后半段的注意力和真实反应质量都会下降。如果有七八个想测的问题,需要回到测试计划阶段,重新排优先级,这一次只选最重要的几个。
任务排序从简单到复杂。第一个任务应该是用户比较容易完成的,帮用户建立对产品的基本熟悉感,进入自然的使用状态,再逐渐过渡到更复杂的任务。把最难的任务放在最前面,用户还没有适应测试环境,行为会更紧张,发现的问题未必是产品本身造成的。
三. 脚本的完整结构
脚本是整场测试的推进框架。它的作用不是让主持人照本宣科,而是确保每场测试的关键内容不遗漏,每场测试之间保持足够的一致性,让不同场次的数据可以比较。

一场可用性测试的脚本结构
1. 开场白
开场白通常在五分钟以内,需要完成几件事:
告诉用户这场测试大概多长时间。说明测试的目的是评估产品,不是评估用户的能力——用户卡住是产品的问题,不是用户的问题,这句话直接影响用户在测试过程中是否愿意说出真实的困惑。询问是否可以录制,说明录制仅用于内部分析,不会对外展示。
然后引导用户进入出声思考的状态:告诉用户在使用产品时,尽量把自己的想法、疑惑、判断说出来,就像是在自言自语一样。大多数用户不习惯边操作边说话,需要在开场的时候明确说明,并且可以用一个简单的示范帮用户理解"出声思考"是什么意思——拿起桌上的一支笔,演示一下"我在想这支笔是谁放在这里的,颜色挺好看,我试一下能不能写",让用户有一个具体的参照。
2. 热身问题
热身问题占五到十分钟,目的有两个:了解用户的背景,以及帮用户进入对话状态。
热身问题问的是用户使用这类产品的背景——多久用一次、通常在什么情况下用、之前用过哪些类似的产品。这些回答对后续分析有参考价值,能帮助理解用户在某个任务里的行为是来自既有习惯,还是来自对这个产品的初次探索。
热身问题不涉及产品评价。如果在热身阶段就让用户说"你觉得这类产品哪里不好用",用户进入任务时已经有了预设立场,行为会受到影响。热身问题只问背景,不问评价。
3. 任务部分
这是测试的核心,占整场测试时间的 70% 到 80%。每个任务的操作流程是:
读出任务背景说明,语调自然,不要用朗读的方式。同时把写有任务内容的卡片递给用户——用户在操作过程中可能忘记任务目标,有卡片在手边可以随时参考。等用户说"我明白了"或者开始操作,主持人进入观察模式,停止主动说话。
任务结束(用户完成或者明确放弃)之后,进行任务后追问。追问的目的是让用户解释刚才的思路——为什么在这里停下来,那个按钮他以为是什么,他最开始想去哪里找。追问用中性的问题,不能包含任何引导:"你刚才在这里停了一会儿,当时在想什么?"——不是"你是不是觉得这里不好用?"
任务和任务之间有简短的过渡语,告诉用户下一个任务的场景即将开始,不评价用户刚才的表现,不剧透下一个任务的内容。
4. 结尾问题
结尾问题在五到十分钟以内,在所有任务结束之后进行。
问用户的整体印象:完成了所有任务之后,对这个产品的整体感受是什么。问用户印象最深的困惑点:如果有一个地方让他们觉得最难用,是哪里。最后给用户一个开放的机会:测试过程中有没有想说但还没有机会说的。
结尾问题的价值在于收集用户的整体评价和自主提出的问题——有些用户在操作过程中遇到了困惑但没有说出来,结尾问题给他们提供了补充的机会。
四. 出声思考法的引导
出声思考(Think Aloud)是可用性测试里最重要的数据收集方式之一。用户的操作行为告诉主持人"用户做了什么",出声思考告诉主持人"用户为什么这样做"——两者结合,才能理解用户的决策逻辑,而不只是记录行为表面。
用户在开始操作后,往往会自然地沉默下来,因为人在操作时不习惯同时说话。主持人需要在不打断任务的前提下,用简短的中性问题唤起用户的出声习惯:"你现在在想什么?"、"这里有什么让你停下来的吗?"——这类问题不引导答案,只是提醒用户把当前的想法说出来。
唤起出声思考的时机要把握好:用户明显在操作但完全沉默超过十秒,可以轻声问一句;用户正在专注操作(手指在移动、眼神在扫描),不要打断,等他们停下来再问。
五. 试测
脚本写完之后,在正式测试开始前需要做一次试测——用一个内部同事或者不相关的人完整跑一遍。
试测能发现的问题比想象中多:任务描述不清晰(试测的人听完任务不知道该做什么);任务时间估算不准确(某个任务实际上要花两倍预期的时间);脚本里遗漏了某个过渡;录制工具需要调整设置;某个任务的完成判断标准不清楚,主持人自己也说不准用户到了什么状态算完成。
这些问题在试测里发现,改动成本是零;在正式测试里发现,轻则某一场数据质量受影响,重则需要重新设计任务、重新招募参与者。所以五到十分钟的试测值得做。
有0人收藏了本文



















