
第1章:认知基础
第2章:比较与排名
第3章:趋势与时间
第4章:比例与构成
第5章:分布与相关性
第6章:流向与变化
第7章:设计决策
第8章:识别误导
去年夏天,我带一个初级设计师做汇报材料,她把公司五条产品线的季度营收做成了饼图,五个扇形各自占着不同的角度,颜色搭配很精心。我看了半天,想确认哪条产品线表现最差,反复在扇形之间比来比去,始终没有把握。我让她换成柱状图,同样的数据,同样的五个数字,结果出来后我第一眼就看到了那根最短的柱子。
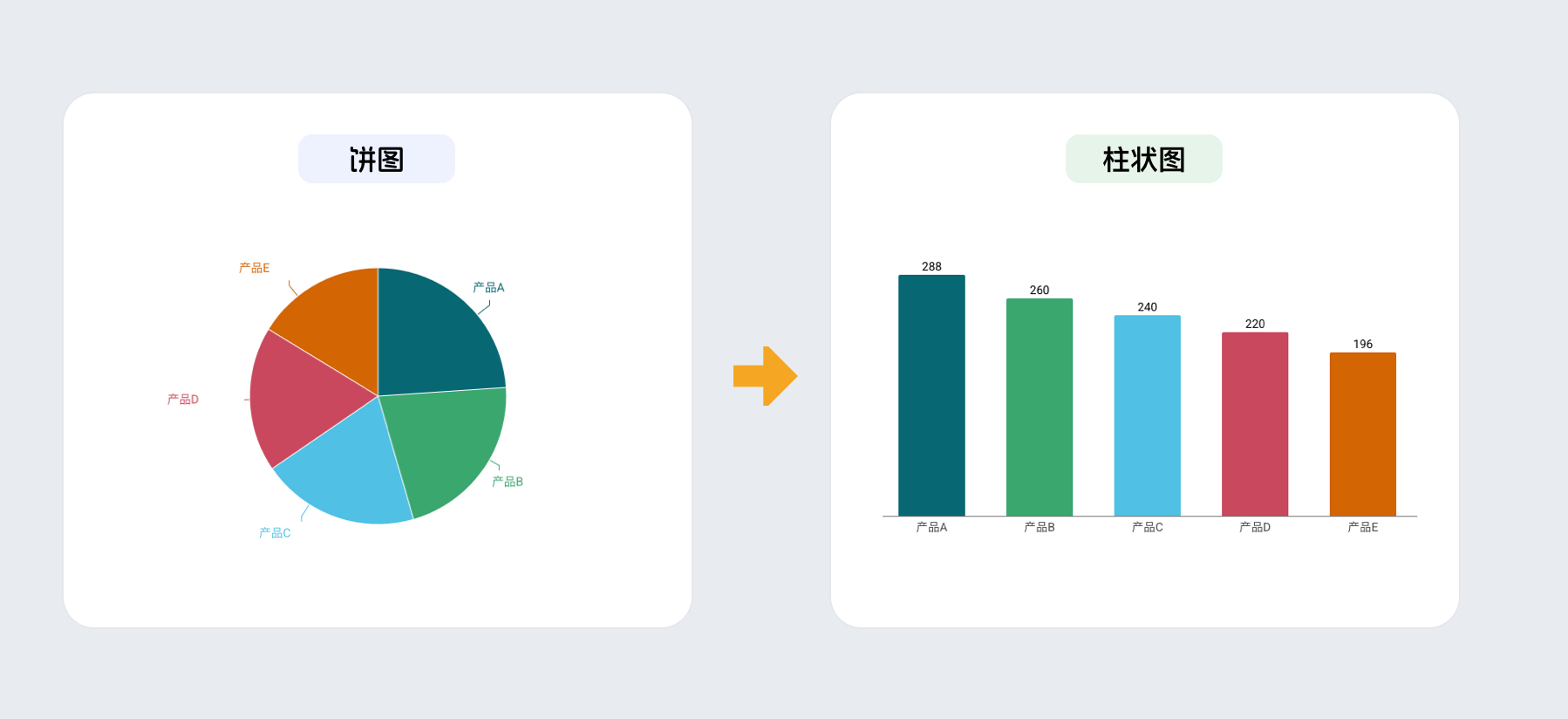
她问我:为什么换一种图表,感觉就完全不一样了?其实答案就藏在数据的传达方式里面。
同一组数据,饼图和柱状图用完全不同的方式把数字呈现给读者。饼图让读者比较角度,柱状图让读者比较长度。角度和长度在视觉感知中的判断精度完全不同,这才是两张图读起来感觉不一样的根本原因。
一. 什么是视觉编码
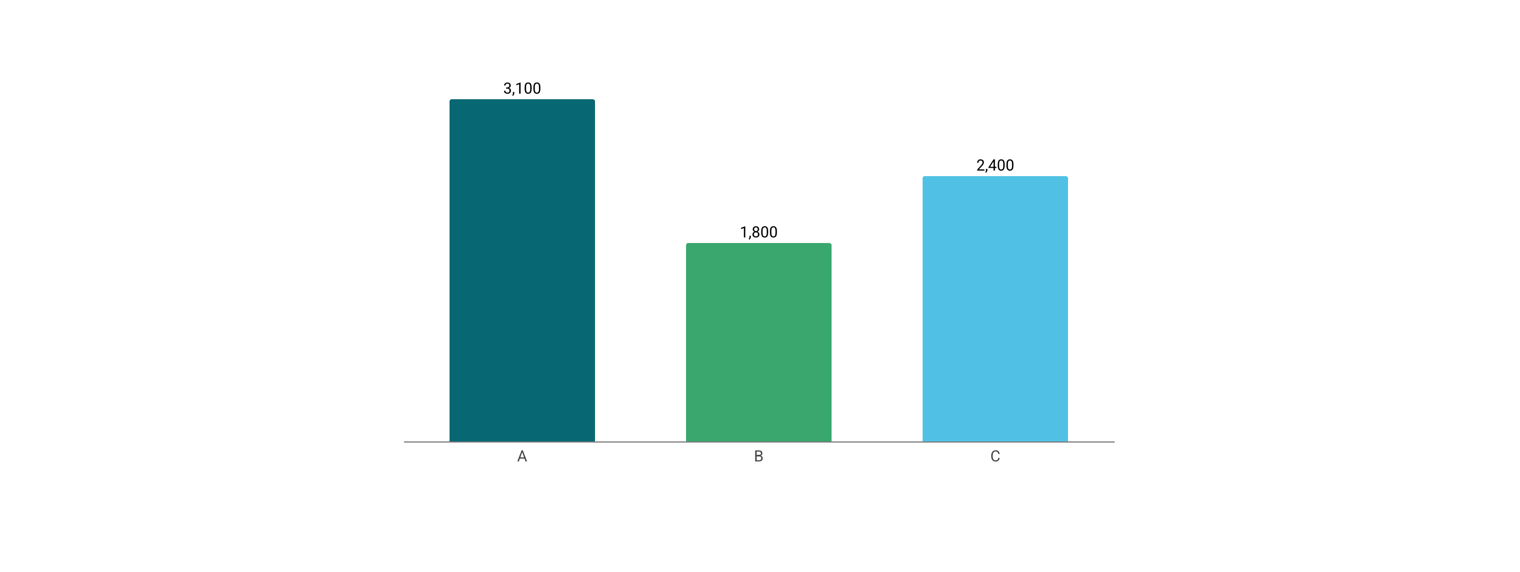
数据本身是抽象的。比如「3100 万」「2400 万」「1800 万」这三个数字摆在那里,任何人都知道它们有大小关系,但感知不到「3100 万比 1800 万大多少」。如果把数字直接呈现给读者,读者需要自己在脑子里做计算。
图表的价值在于把这个关系变成人眼能直接感知的内容。柱状图把 3100 万画成一根高柱子,把 1800 万画成一根矮柱子,两根柱子并排放在那里,任何人都不需要计算,眼睛就可以直接感知到「这根明显比那根高很多」。把数值映射到某种视觉属性上,这个过程就叫做视觉编码。
视觉属性有很多种:长度、位置、角度、面积、颜色深浅、颜色种类、形状、方向等……每一种都可以拿来承载数据。柱状图用的是长度,饼图用的是角度,散点图用的是位置,气泡图用的是面积,热力图用的是颜色深浅。图表类型的本质,就是选择以某一种视觉编码方式,把数值翻译成对应的视觉属性。
但不是所有视觉属性都一样好用。两根柱子的长度差,一看就能判断出来;两个扇形的角度差,很多人确经常看走眼;两个圆的面积差,更是系统性地估不准。选了判断精度高的属性(比如长度),读者读图又快又准;选了判断精度低的属性(比如角度、面积),读者读图费力,还很容易读错。图表好不好读,很大程度上取决于设计师选了哪种视觉属性来承载数据。
二. 视觉编码的可靠性排序
认知科学家克利夫兰(William Cleveland)和麦克吉尔(Robert McGill)在 1984 年做了一系列实验,让受试者比较图表里两个数据点的大小关系,记录判断误差。这项研究给出了一个视觉编码可靠性的排序,从最精确到最模糊,这个排序在今天仍然是图表设计领域最重要的理论依据之一。
1. 长度和位置:最可靠
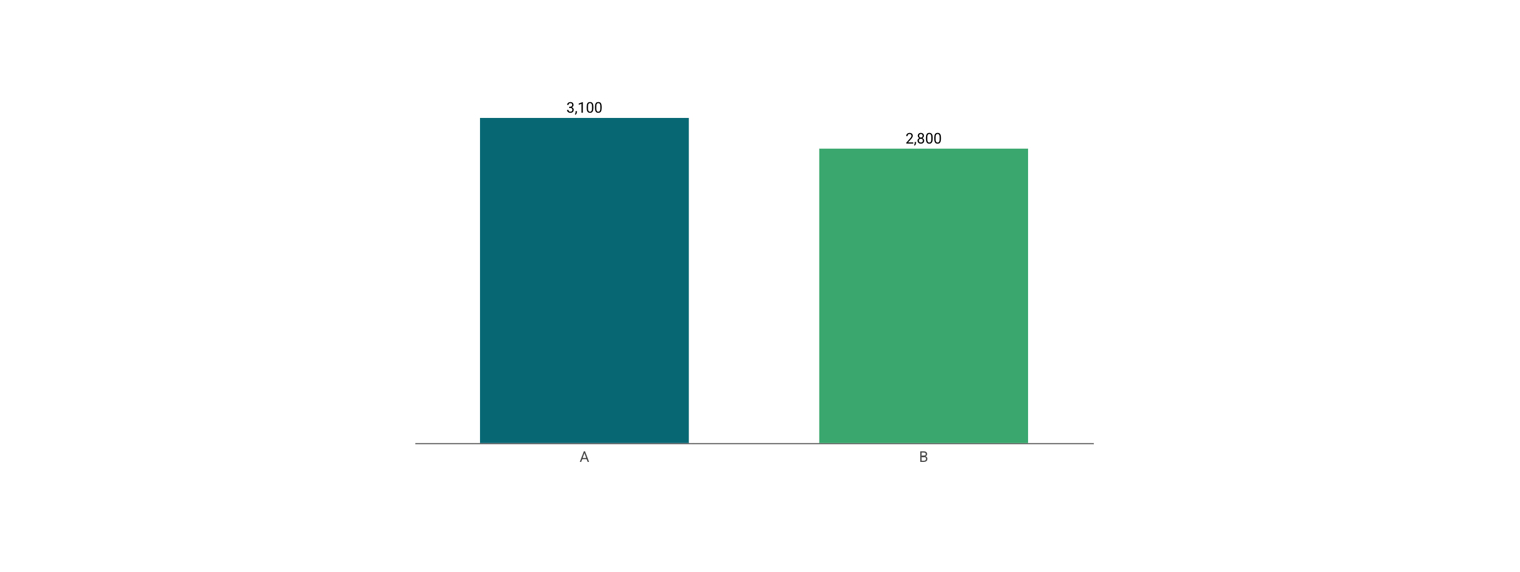
当两条线段从同一条基准线出发,读者判断它们长度的差距几乎不会出错。普通柱状图的精确性也来源于此。所有柱子都从同一条底线开始,读者比较的是各自的高度,这个判断非常自然。
下面我们用具体数字来做说明。把「北京 3100 万、上海 2800 万」人口做成柱状图,两根柱子的高度差在视觉上很清晰,读者不需要计算,眼睛能直接感知到大约 10% 的差距。这个判断是自动发生的,不需要任何思考。
位置的判断同样准确。散点图把每个数据点放在一个 x-y 轴坐标系里,读者感知到点的位置,其实是在同时判断两个维度上的精确值。散点图之所以能展示两个变量之间的关系,就是因为位置编码让读者能够精确感知每个点在两个维度上各处于哪里。
2. 角度:开始出现误差
视觉系统判断角度的准确度明显低于判断长度。饼图的全部数量信息来自扇形角度,这是饼图读取效率低的根本原因。不是因为饼图难看,而是因为我们对角度的感知本来就不精确。
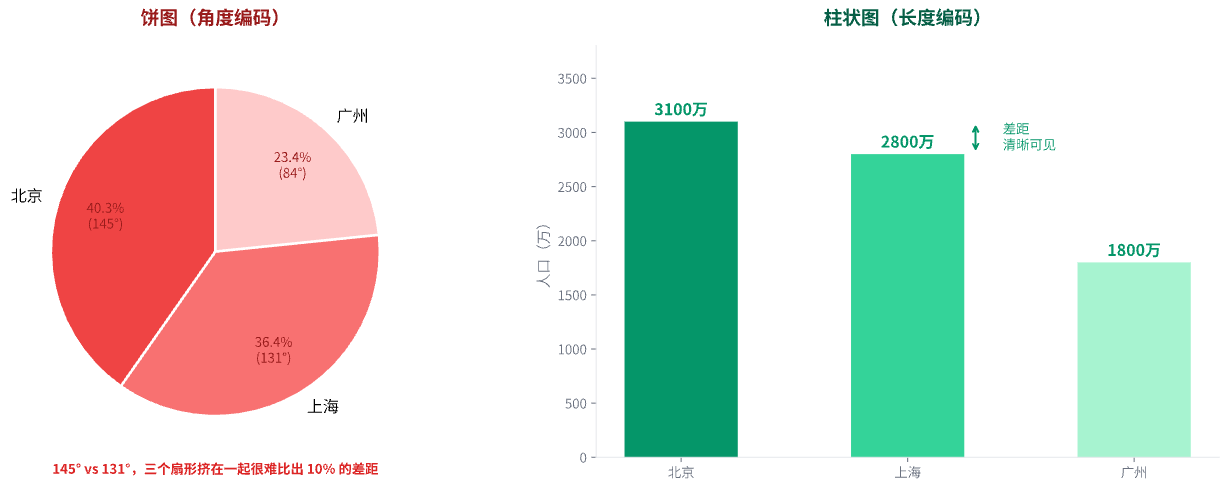
加入第三个城市再来看。「北京 3100 万、上海 2800 万、广州 1800 万」做成饼图,三个扇形角度分别是 145 度、131 度和 84 度。广州明显最小,但北京和上海差了多少?145 度和 131 度只差 14 度,三个扇形挤在一起,大多数人看不出北京比上海大了 10%。
如果五个扇形的角度都在 60 度到 80 度之间,读者连哪个扇形最大都可能判断错。这不是读者不认真,而是视觉系统对这个精度范围的角度判断本来就容易出错。
还有一个让饼图更难读的问题。起始角度和位置会影响视觉判断。同样是 90 度的扇形,放在 0° 到 90° 和放在 45° 到 135°,读者对它的感知是不一样的。研究显示,接近 0°、90°、180°、270° 这四个方向的扇形,角度判断相对准确;斜角方向的扇形判断误差更大。饼图里的分类通常不会恰好落在这几个方向上,所以读者的判断误差是普遍存在的。
3. 面积:误差更大,还有系统性偏差
气泡图用圆的面积来表达数量,这是一种面积编码。视觉系统对面积的感知本来就不精确,而且存在系统性低估。面积比实际看起来更小,尤其是当面积差距很大时,小圆圈看起来比实际占比更不显眼。
面积编码容易在两个环节出问题,方向相反但都会导致误读。
第一个问题出在读者的感知端。即使气泡大小按面积正确计算了,读者仍然会低估差距。比如 A 产品线季度营收 8000 万,B 产品线 2000 万,实际差距是 4 倍。做成气泡图之后,A 的气泡直径是 B 的 2 倍(面积 = πr²,面积 4 倍对应半径 2 倍)。读者看到一个圆的直径是另一个的两倍,直觉感受是"A 大概是 B 的两倍",而不是实际的 4 倍。
第二个问题出在设计师的制作端。如果设计师按直觉把半径做成两倍来表达"数据是两倍",圆的面积其实变成了四倍,反而夸大了差距。要让一个圆的面积是另一个的两倍,半径只需要增加到根号 2 倍,大约 1.41 倍。不按面积公式计算而凭直觉调整大小,气泡图的数据误导几乎是必然的。
4. 颜色深浅:只能表达量级,不能表达精确差异
热力图用颜色深浅来表达数值高低。颜色最深的格子和颜色最浅的格子,读者能感知到「高」和「低」,但两个深度接近的颜色之间的差距,几乎不可能估算准确。
比如一张销售区域热力图,某个区域是深蓝,另一个是稍浅的蓝,读者知道深蓝区域更高,但说不出高多少。是 10%?20%?50%?颜色深浅没有内置的精度感。
颜色深浅适合的任务是让读者感知「哪些区域明显更高,哪些区域明显更低」。如果读者需要知道精确的差距,颜色深浅是错的编码方式,应该在颜色深浅的基础上叠加数字标注,或者换成其他精度更高的图表类型。
5. 颜色种类:完全不表达数量,只区分类别
红色和蓝色之间没有大小关系。用颜色种类来表达数值高低,是图表设计里一种严重的误用。读者看到一排不同颜色的柱子,会自然尝试从颜色里寻找规律。这个颜色代表高?那个颜色代表低?但颜色种类根本不承载这个大小信息,读者是在白费力气。
颜色种类最正确的用途是区分类别。比如这条折线是 A 产品线,那条是 B 产品线;这组散点是 20 岁以下用户,那组是 20-35 岁用户。颜色告诉读者「这些点属于哪个组」,但不表达任何数量上的差异。
四. 饼图和柱状图的差距在哪
现在可以回答本文开头的问题了。饼图用角度表达数据,柱状图用长度表达数据。角度的判断精度远低于长度的判断精度。同样的五个数字,饼图让读者做角度判断,柱状图让读者做长度判断。视觉系统在长度判断上更擅长,所以柱状图读起来更准确也更省力。
但柱状图并不是在所有场景下都比饼图有优势。饼图适合的场景不是「比较五个数值的大小」,而是「展示一个明显占主导的部分在整体中的比例」。如果只有两个分类,一个占 70%,另一个占 30%,饼图能让读者直觉感知到「这个占大多数,那个只占小部分」,这个场景任务不需要精确判断,角度足够了。
五. 选图表之前先问什么
拿到数据想做图表,很多设计师的第一个问题是「这组数据适合用什么图表来表示」。这个问题问得不够正确,正确发问是,读者看完这张图需要得出什么结论,这个结论需要多高的判断精度。
如果需要比较各类别的大小,而且需要看清楚差距有多明显,这个需求要求高精度判断,用长度编码,选柱状图或横向条形图。
如果需要感知某个指标随时间的变化趋势,关注的是增长还是下降、变化快还是慢,不需要精确读出每个时间点的数值,用折线图的斜率编码更直接。
如果需要看两个变量之间有没有相关性,散点图用位置编码,可以让读者感知点的分布方向,有没有随着 x 增大 y 也增大的趋势。这个结论不需要精确读出每个点的坐标,有位置的相对分布就足够了。
如果需要看某个指标在地理区域上的分布,哪些省份集中、哪些省份稀疏,这个需求可以接受模糊判断,颜色深浅配合地图,就能给出足够的答案。
同一组数据,问的问题不同,图表类型就要跟着换。
拿一份用户年龄分布数据来举例。设计师想让读者看清「各年龄段分别有多少人」,这需要精确比较每段的数量,用直方图或柱状图。设计师想让读者看到「用户年龄主要集中在什么区间」,重点是分布的集中趋势,用箱线图或密度图。设计师只想传达一个大致印象「年轻用户多还是老用户多」,一条平均值线加分布标注就够了。三个问题对判断精度的要求依次降低,适合的图表类型也完全不同。
六. 同一组数据,不同的图表在讲不同的事
同样是「五个城市的季度销售额」,可以做成竖向柱状图,可以做成横向条形图,可以做成气泡放在地图上,可以做成有颜色深浅的表格。这些方式传达的侧重点不同。
竖向柱状图把读者的注意力引向「五个城市各自是多少、谁高谁低」。
气泡地图把读者的注意力引向「哪个地区的销售额集中、地理上的分布格局是什么样的」。
颜色深浅表格把读者的注意力引向「哪些城市在哪些季度表现突出,有没有规律」。表格能同时展示城市和季度两个维度,颜色深浅帮助读者快速定位高值区域。
如果一张图试图回答所有这些问题,通常会变成一张信息过载、读者不知道该看哪里的图。设计师的工作是选择一个最重要的问题,为这个问题选择最合适的视觉编码方式,让读者在看图的前几秒就能得到答案。
七. 颜色的陷阱
设计师拿到一张柱状图,习惯性地给每根柱子配一种颜色,觉得这样「更好看」。但颜色种类本身是一种信息通道,它承载的信息是类别区分。当每根柱子都是不同颜色,读者的视觉系统会自动尝试从颜色差异里找规律。这个颜色代表什么特别的含义?为什么绿色的柱子在这里?
如果颜色没有任何含义,只是装饰,读者在无效地消耗认知资源,而且会隐约感到困惑。好的图表不会让读者做任何毫无意义的解读工作。
颜色在图表里正确的用法有两种:一是区分系列(这条折线是 A 产品,那条是 B 产品),二是高亮重点(五根柱子用灰色,需要读者关注的那根用蓝色)。用颜色「装饰」同一系列的多个数据点,是把一个信息通道用于传达「没有信息」,结果只会是增加噪音。
八. 那些图表规则从哪来的
理解了视觉编码的可靠性排序,后面很多图表规则就有了来处。
- 柱状图的 Y 轴必须从零开始。因为柱状图用长度编码,Y 轴截断会改变柱子的实际长度,直接破坏了视觉编码的准确性。
- 折线图为什么可以不从零?因为折线图传达的是斜率(变化速度),不是绝对长度,Y 轴截断不改变斜率,不破坏折线图的视觉编码。
- 饼图不能超过五六个分类。因为饼图用角度编码,分类越多,每个扇形的角度越小,角度判断的误差越大,小扇形几乎完全不可读。
- 气泡大小要按面积计算,不能按半径。因为气泡用面积编码,半径和面积不是线性关系,按半径设置大小会引入额外的误差。
- 热力图要配色阶说明。因为颜色深浅的判断本来就不精确,如果没有色阶帮助读者把颜色值对应到具体数字,颜色深浅只能传达「大概的高低」,不能传达任何精确信息。
以上这些规则都不是凭空而来的,都是视觉编码可靠性在具体图表类型上的应用。知道了背后的原因,遇到规则没有覆盖的新情况时,设计师就可以回到视觉编码的可靠性排序上,自己判断该怎么处理。