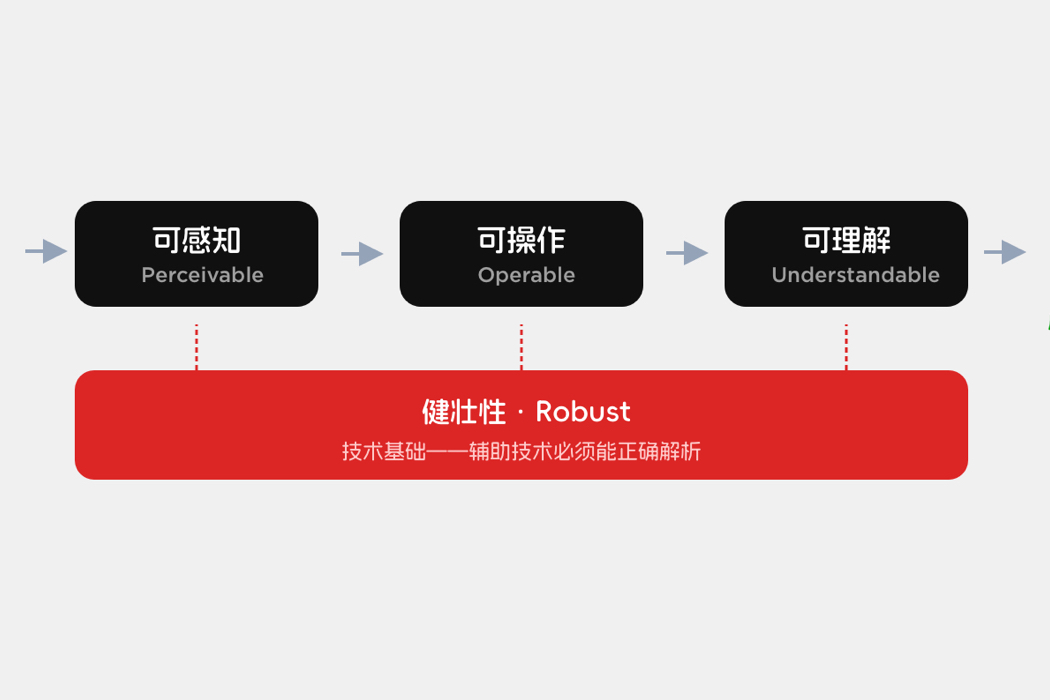
在很多界面里,信息并不总是以文字出现,有时会以图标按钮、角标数字、红点提示、状态图形、促销 banner、流程示意图、数据图表等形式出现,对于视觉正常的用户,这些内容看起来都很直观,通常可以通过颜色、形状、位置与层级进行区分。但一旦用户无法依赖视觉进行正常浏览,那么这些信息就会突然断层。界面尽管仍然存在,但关键含义却像被抽走了一部分一样。
文本替代要做的事,就是把这类完全依赖视觉传递的信息,用文字补齐,让信息可以被用户从另外一条通道理解。它不是给图片写一段外观描述,而是把图片或图形在当前场景里承担的意义交代清楚。用户不必完全借助于眼睛,也能知道这是什么、它表达了什么、点了会发生什么。
文本替代最直接的受益者,是盲人和重度低视力用户,他们通常会借助屏幕阅读器来浏览和操作界面。对于这些用户而言,文本替代决定了界面产品是否完整。如果没有文本替代,他们借助读屏器听到的内容,可能只是“按钮”、“图像”、“未标注”,这样用户很难形成可靠的理解,更谈不上顺利完成任务。
文本替代的重要意义并不局限盲人和重度低视力用户。当图片加载失败、网络不佳、强光下看不清、正常视力的用户也只能通过键盘操作、接收语音提示的方式快速定位信息,在这种情境下,文字表达就会变得极为重要。文本替代让同一份信息能够被转成语音、盲文或其他形式,这也是它被放在可感知里的原因。
要想真正讲清文本替代,就绕不开屏幕阅读器。因为屏幕阅读器是检验文本替代是否有效的一把尺子。
1. 屏幕阅读器
屏幕阅读器是一种辅助技术。它把屏幕上的内容转化为语音或盲文,让用户即使不依赖视觉,也能理解界面并完成操作。它看上去像是在朗读页面,但它并不会像人一样看图识字,更不会理解渐变、阴影、对齐、留白这类纯粹的视觉表现。
屏幕阅读器真正读取的,是浏览器与系统提供的无障碍语义信息。你可以把这层信息理解为界面的语义骨架,它决定了用户“听到的界面”长什么样。通常,这套语义会包含几类关键内容。
1. 元素类型。读屏器会告诉用户当前对象是按钮、链接、输入框、标题、列表项,还是图像。
2. 元素名称。也就是读屏器实际朗读出来的那句话。图标按钮往往会被读成搜索、返回、更多操作之类的名称;图片则通常依赖其替代文本来提供可读的内容。
3. 状态信息。已选中、不可用、展开或收起、是否存在错误、是否有未读数量,这些都属于状态。对视觉用户而言,它们可能只是颜色或样式的轻微变化;但对读屏用户而言,若没有用语义明确表达,用户就无从得知界面发生了什么。
4. 结构与顺序。读屏器通常沿着可聚焦元素的顺序前进,从一个可操作对象移动到下一个对象。视觉用户可以同时扫视多个信息点,而读屏用户更像沿着一条线索逐步推进,一旦顺序混乱,用户就很容易在听觉路径里迷失方向。
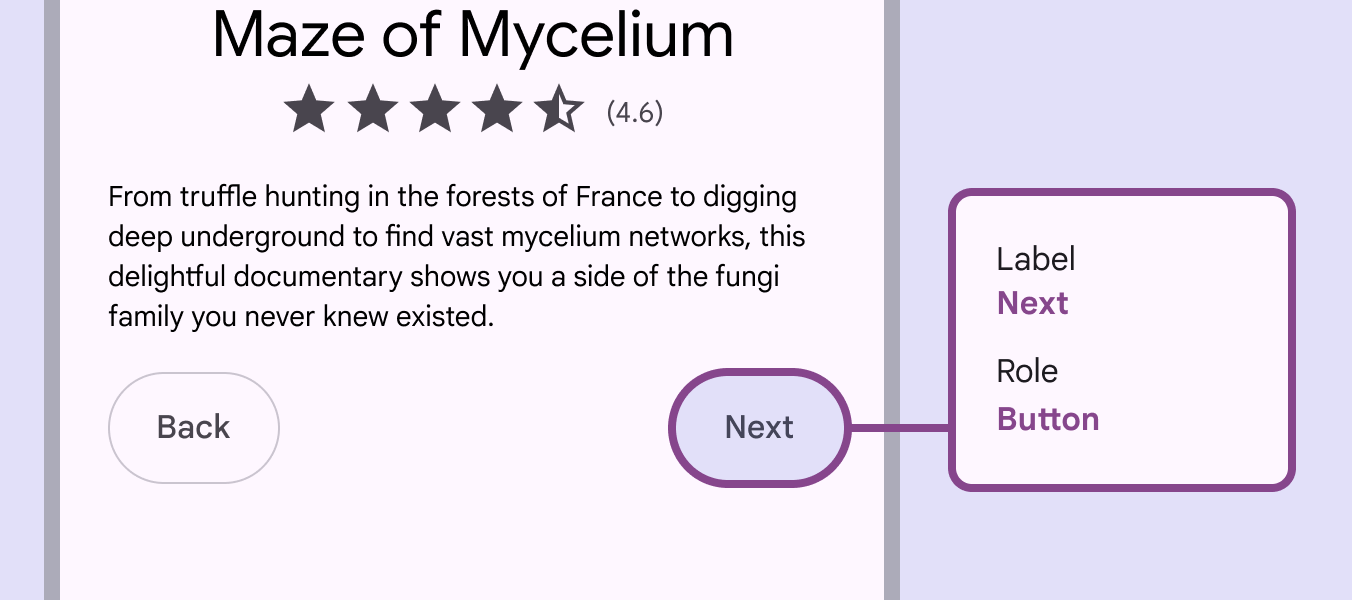
M3无障碍规范中,关于按钮可被读取的标签元素
屏幕阅读器的工作机制,为我们带来一个非常重要的结论:屏幕阅读器读的不是你画出来的画面,而是你和研发共同交付给浏览器的语义信息。文本替代正是在这层语义上补齐缺失的含义,让界面在读屏的路径里不出现空白与断点。
2. 文本替代
有了对屏幕阅读器的基础了解,我们回到WCAG可感知:文本替代的讲解。
在 WCAG 的可感知原则下,文本替代的要求其实可以归结为一句话:只要某段内容不是以文字呈现,却承载了信息或功能,就必须给它配上一份等价的文字表达,让这些信息能被转换成用户需要的形式。
这里有两个要点,需要特别注意。
第一,所谓等价,并不是说外观要被“翻译”出来,而是说信息要等价。视觉用户能理解什么、能据此做出什么操作,读屏用户也应该获得同样的理解与行动依据。
第二,非文本内容也远不止图片。图标按钮、角标、红点、状态图形、图表、信息图、以及图片里写着的文字说明,都在这个范围之内。
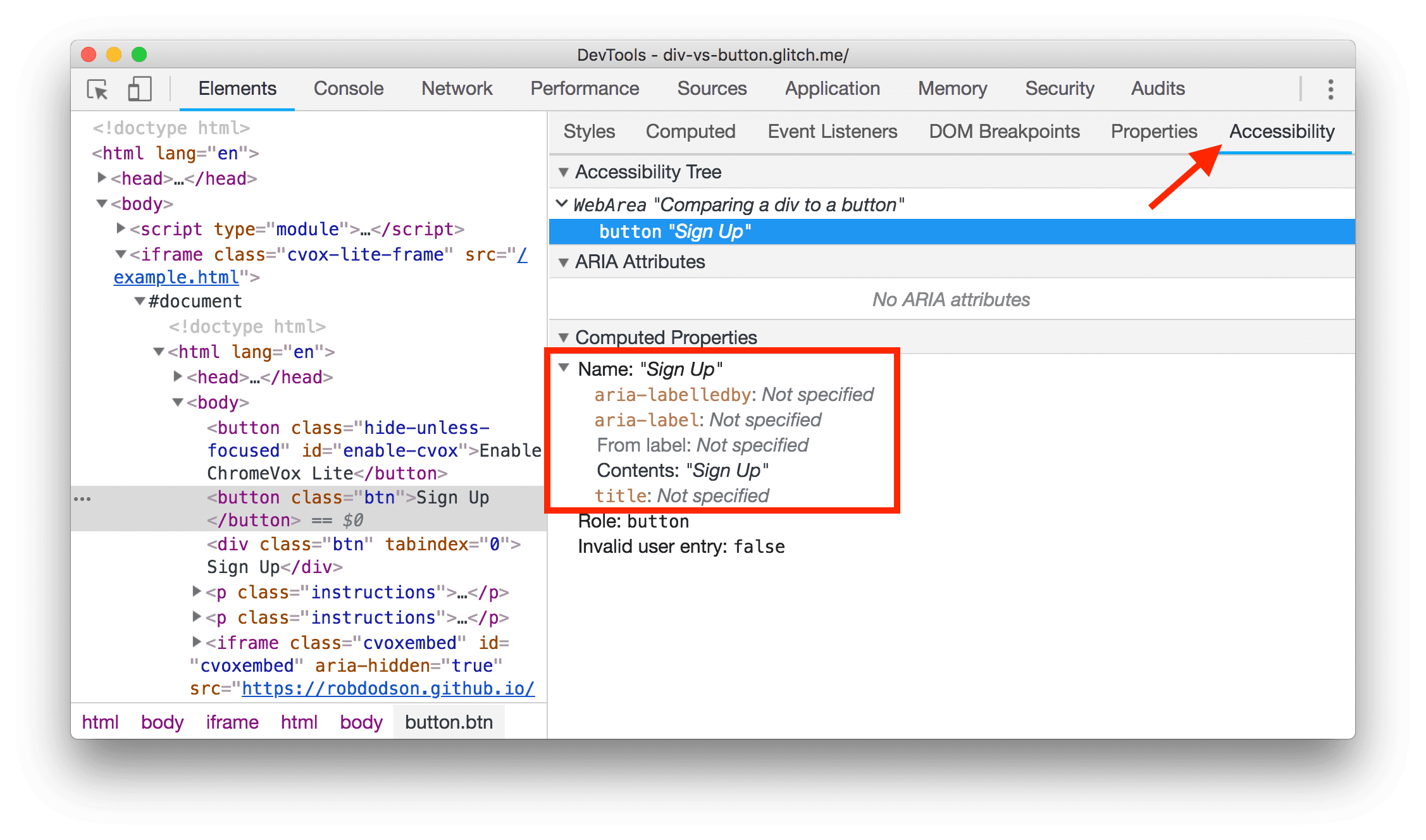
在 Chrome 的开发者工具中查看元素的无障碍名称,研发就是将文本替代添加在这里
为了让写法明确,我们需要最先确定一件事:这个元素在当前界面里扮演什么角色。角色不同,写法就不同。
2.1 可操作元素
如果它是可操作的元素,也就是用户能点击或触发它,那么文本替代就要把它的作用说清楚。纯图标按钮不要描述图标长什么样,而要直接交代它要完成的动作。

放大镜不必被称作放大镜,它更应该被读成搜索。三个点不必被称作三个点,它更应该被读成更多操作。垃圾桶也不是垃圾桶,它应该是删除。若操作带来明显后果,名称就要更具体一些,例如删除照片、清空购物车、提交订单。名称清楚,用户听到后,才会知道按下去会发生什么,才敢点击。
2.2 信息提示与状态
如果它是在提示信息或表达状态,那么只靠视觉传达的内容,就需要被翻译成文字。红点不是红点,它在说有未读消息。角标上的 3 也不是数字 3,它在说有 3 条未读通知。对勾意味着已完成,感叹号意味着有错误需要处理。
这里常见的误区是只用颜色区分状态,例如用红色表示错误、用灰色表示禁用。视觉不受限的用户能清晰分辨,但读屏用户听不到颜色。所以只要状态可能会影响理解或操作,就应该提供对应的状态文本。
2.3 图片、banner、插画、图表
至于图片、banner、插画与图表,关键在于它们是否承载信息。装饰性图片不影响理解,就应当保持安静,避免读屏反复播报。
信息型图片则需要提供等价信息,促销 banner 上写的关键内容,应该在文本替代里出现。流程示意图、说明海报或信息图如果一句话放不下,更合理的做法是先给出简短说明,再在图片附近提供更完整的文字解释,用步骤或列表把信息展开。图表也是同样的逻辑。重点不在于描述线条如何起伏,而在于给出结论与关键数值。读屏用户不该只听到这是一张折线图展示趋势这种空话,更有用的表达是过去六个月总体上升,12 月达到 120 万,11 月为 98 万。只要听到这句话,用户就能把握图表的核心含义。
2.4 表单错误提示
表单错误提示则更需要直接。不要只告诉用户出错了,而要说清楚哪里错、怎么改。手机号格式不正确,请输入 11 位数字,这类句子短,但足够指导行动。输入有误这种话虽然常见,却很难真正帮到读屏用户。
把这些写法串起来,你会发现文本替代并不神秘。它更像是在做一次信息补全:你把视觉传达的含义,用文字重新交代一遍,并确保这份文字与界面行为一致。这样一来,不管用户用眼睛看,还是用读屏器听,得到的都将是同一份可理解、可操作的内容。
3.设计交付物
很多新手会担心,自己不写代码,就做不好无障碍。其实在文本替代这件事上,设计师完全可以通过交付物把这部分要求交代清楚。设计师不必替研发决定属性该怎么写,也不必在实现细节上与研发反复拉扯。设计师更关键的工作,是把该被读出的文字和该被理解的信息交代清楚,让研发拿到的是一份有明确目标、可直接落地的需求。
一份更完整的交付物,至少应当包含四类与文本替代紧密相关的内容。
3.1 图标与控件的名称清单
只要控件只有图标,没有可见文字,交付物里就必须补上它的读屏名称。名称要使用产品面向用户的语言,不要把中英硬塞进同一句里。中文产品就写搜索、返回、关闭、更多操作、分享、下载、删除;英文界面则提供对应英文版本,并通过多语言资源分别输出。这样做的目的很简单,用户听到的应当是意义,而不是图标本身。
3.2 状态文本与触发时机
设计稿里很多状态靠颜色、角标或图形来表达,但这些线索并不会被读屏器自动理解。设计师需要把视觉状态翻译成文字状态,并写清它在什么时候出现、在什么时候消失。未读红点对应有未读消息,数字角标对应几条未读,禁用态对应不可用,选中态对应已选中,加载对应加载中,成功提示对应已加入购物车或已保存。同时,触发时机也要交代清楚,例如用户点击消息入口后未读角标是否清除,提交失败时错误提示是在字段旁显示,还是在页面顶部集中提示。状态写得明白,用户的操作才更踏实。
3.3 是图片与图表的等价信息
信息型图片旁边应当有一段等价文字,你可以把它写成标注块贴在图旁,也可以整理进文案表,关键是让信息有一份可复制的文字版本。图表则至少提供一句结论,再补上关键数字,帮助读者在不看图的情况下也能抓住要点。复杂的信息图可以先给简短说明,再在附近补充更完整的文字解释,用步骤或列表把信息展开。至于装饰图,则需要明确标注为装饰,避免被朗读打断阅读节奏。
3.4 读屏顺序相关的关键说明
文本替代的核心在名称与信息,但交付物最好再补一句焦点顺序要求,尤其是弹窗、底部抽屉、复杂表单和卡片列表这类结构更复杂的界面。读屏用户是沿着顺序一步步走的,顺序一乱,理解就会被打散。你不必画一张巨细无遗的流程图,只要把打开后的焦点落点、关闭后的返回位置、表单字段的自然顺序写清楚,验收时就更容易定位问题。
为了让团队执行起来更轻松,你可以在 Figma 里建立一个固定的标注块,用少量字段把关键信息锁住,例如元素、读出文本、是否装饰或是否需要朗读、状态触发说明。设计师每做一个页面,只要把这些项补齐,就等于把文本替代的要求稳稳地写进了交付物里,也把“应该读到什么”这件事讲得很清楚。
4.小结
文本替代之所以重要,是因为界面里有太多信息是靠视觉在传递的。屏幕阅读器读取的并不是像素,而是界面在语义层提供的内容。只要这些信息没有以文字或可被识别的语义形式存在,读屏的路径里就会出现空白,用户既难以建立理解,也缺少继续操作的依据。
回到 WCAG 的可感知原则,文本替代要求我们为非文本内容提供等价信息。可操作元素需要把用途说清楚,让用户听得懂它能做什么;状态提示需要把状态讲明白,让用户知道界面发生了什么变化;信息型图片与图表需要把关键信息补出来,让用户不看画面也能抓住要点;装饰性内容则应当保持安静,避免在朗读中反复打断。设计师不必承担实现细节,但设计师必须在交付物里把应读出的文字与状态规则写清楚,让团队拿到明确且可执行的目标。
当你把文本替代看作一次信息补全,而不是一项形式任务,它就不再是额外负担。它会成为一种更可靠的表达方式,让同一份信息在不同的感知方式下都能成立,也让更多用户真正走得通、用得顺。
有0人收藏了本文